
Uma pergunta que frequentemente recebo e tenho em nossos treinamentos é com relação a Badchars, o que são, como são causados, e como encontrar. Neste post irei comentar com mais detalhes sobre este assunto.
Badchars, ou caracteres inválidos, não tem uma definição formal, mas é frequentemente utilizado para referenciar caracteres inválidos no processo de criação de exploits. Mas e dai? Continuei sem entender!
Em poucas palavras e de forma direta badchar é todo caractere que quando passamos em um processo de exploit cause um dos comportamentos abaixo:
- Não seja salvo em memória (desapareça);
- Seja salvo um valor diferente do passado (altere); Ex.: mandamos o caractere A mas na posição em memória é salvo B;
- Adicione um caractere adjacente antes ou depois do caractere atual (se expanda); Ex.: mandamos o caractere A mas na posição em memória é salvo AB ou BA;
Vamos detalhar este processo. Observe a imagem abaixo:
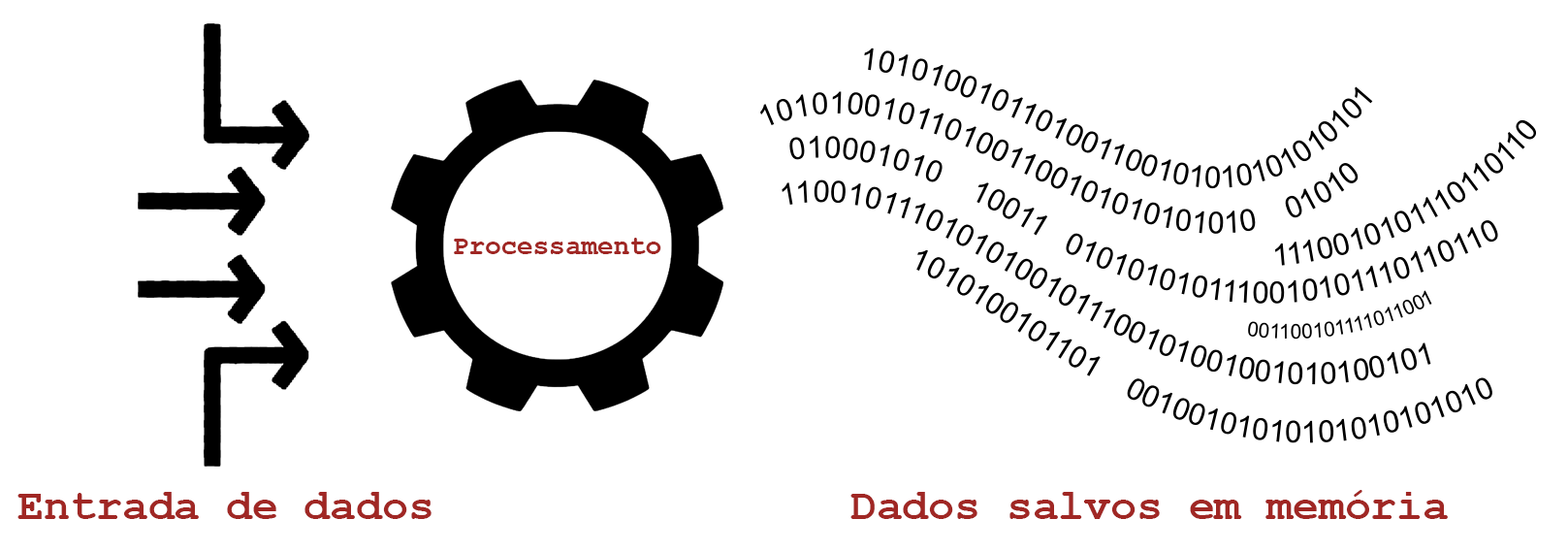
Na imagem podemos ver que temos uma ou mais entrada de dados que passam por algum tratamento por parte da aplicação e posteriormente são salvos em memória. O badchar ocorre exatamente no ponto de recebimento e tratamento dos dados, e é diretamente ligado a como a aplicação foi escrita.
Em uma aplicação, por exemplo, onde o campo que temos para passar dados é o campo HOST do cabeçalho http. Este campo por definição só deve aceitar um range pequeno de caracteres (A-Z, a-z, 0-9, ç, ., -, _ e etc…) mas não deve aceitar caracteres como quebra de linha (\r), retorno de carro (\r) entre outros. Se levarmos em consideração este caso, e se aplicação tiver implementando uma filtragem diversos caracteres (não pertencentes a estes caracteres permitidos) não serão salvos em memória. Desta forma estes caracteres que causam um dos comportamentos anômalos listados acima.
Sendo assim, então basicamente o badchar é causado por um comportamento da aplicação (filtro, forma de cópia, tratamento e etc…) em que altera os dados entre o seu recebimento e o seu armazenamento em memória.
Identificando badchar
O processo de identificação de badchar basicamente consiste em enviar os dados para a aplicação e posteriormente verificar os dados armazenados em memória validando se o que foi passado realmente é o que foi salvo em memória.
Identificando badchar no windows
Para identificação de badchars em um processo de criação de exploit no windows nós temos um post explicando este processo, desta forma segue aqui o link do mesmo: Criação de Exploits - Parte 2 - Removendo bad chars usando Immunity Debugger e Mona
Identificando badchar no linux
Para identificação de badchars em um processo de criação de exploit no linux o procedimento é basicamente o mesmo realizado no windows, sendo assim recomendo que realize a leitura do tutorial acima. Porém no linux ao invés de utilizar o mona para realizar a criação do bytearray e comparar os dados (!mona bytearray e !mona compare) utilizamos os comandos bytearray e bincompare implementados por mim nos scripts adicionais do GEF (explico a instalação do mesmo neste tutorial Buffer Overflow Linux - Melhorando o GDB).