
Neste post irei inaugurar uma nova seção do site onde postarei uma série de tutoriais de como realizar a criação de exploits, a maioria deles, utilizando Buffer Overflow.
Caso você deseje segue o link para a lista completa de posts sobre a criação de exploits e buffer overflow: https://www.helviojunior.com.br/category/it/security/criacao-de-exploits/
Mas antes de começar a colocar a mão na massa, como sempre, precisamos de um pouco de teoria para embasar e entender todo o contexto, e como quando falamos de Buffer Overflow, falamos de memória, pilha, push pop, assembly e etc… nada é tão simples e tão trivial, então se posso dar uma recomendação é: leia e releia toda a teoria, busque outros sites, outros livros, outras referencias para complementar o seu conhecimento, pois isso será base para o sucesso ou falha no momento da criação dos seus exploits.
Segue a referência de um site onde tem bastante conteúdo sobre este assunto: https://www.corelan.be
Antes de mais nada, o que é Buffer Overflow?
Weidman define Buffer Overflow como “o processo pelo qual manipulamos a memória de uma aplicação de forma que preenchemos mais dados do que a aplicação esperava receber extrapolando o tamanho da variável no stack de memória e sobrepondo o espaço de memória adjacente”. Se um pedaço de memória crítica for sobreposta a aplicação irá falhar/gerar uma exceção/erro. Com um pouco de técnica e cuidado podemos sobrepor partes importantes e controlar o fluxo de execução da aplicação após essa falha.
Definição de ambiente
Antes de mais nada é importante ressaltar que todos os procedimentos que explicarei nessa série de posts são baseados em Microsoft Windows com aplicação rodando em 32 bits.
Arquitetura e Memória
Antes de ir a fundo em Buffer Overflow e criação de Exploits certamente precisamos entender como a memória funciona, pois o princípio base de Buffer Overflow é a manipulação de memória. Nosso objetivo final sempre será manipular a memória de forma que aplicação execute o que vamos inserir nela.
Quando se estuda a arquitetura de um ambiente computacional há uma sistema hierárquico de proteção conhecido como Protection Ring, basicamente isso é um mecanismo de proteção e tolerância a falhas dos sistemas. Em um ambiente Windows 32 bits o endereçamento de memória vai de 0x00000000 a 0xFFFFFFFF, onde se divide em duas faixas: a primeira que vai de 0x00000000 a 0x7FFFFFFF é atribuída ao Ring 3 - User-land, e a segunda vai de 0x80000000 a 0xFFFFFFFF que é atribuída ao Ring 0 - Kernel-land. O Endereçamento de memória dentro do kernel-land somente é acessível pelo Sistema Operacional.
O Windows utiliza um modelo de endereçamento de memória conhecido como flat memory model, que basicamente indica que a memória aparece para as aplicações como um único espaço contínuo. A CPU pode diretamente (and linearmente) endereçar toda memória disponível sem a necessidade de utilizar segmentação/paginação de memória.
Memória
Primeiro precisamos entender um pouco mais como é a memória de um aplicativo, veja a imagem abaixo:
[caption id=”attachment_1826” align=”alignnone” width=”300”] Visualização da memória[/caption]
Visualização da memória[/caption]
Cada aplicação utiliza parte da memória, a aplicação contém basicamente alguns segmentos de memória, conforme abaixo:
- segmento de código (text): código do programa a ser executado
- segmento data: informações globais da aplicação, estes dados são carregados no momento do início da aplicação, são estáticos (não mudam enquanto o programa está rodando) e estão disponíveis para a toda a aplicação
- segmento pilha (stack): tem tamanho fixo e é usado para armazenar argumentos das funções e variáveis locais.
- segmento heap: armazena as variáveis dinâmicas
Embora a imagem mostre varias seções ordenadas, não existe uma garantia que essa ordem sempre será a ordem na sua aplicação pois elas podem ser alocadas em qualquer ordem desejada.
Em uma arquitetura baseada em Intel x86 (32 bits) temos os seguintes registradores de uso geral:
- EAX : acumulador : utilizado para realizar cálculos e para armazenar valores de retorno em chamadas de função. Operações básicas como adição, subtração e comparação utilizam este registrador
- EBX : base : Não há um propósito geral para este registrador, mas pode ser utilizado para armazenar dados
- ECX : contador : utilizado para interações/laços/loops. ECX conta de forma decrescente.
- EDX : data : ele é uma extensão para o EAX pois possibilita calculos mais complexos como multiplicação e divisão permitindo o armazenamento de dados extras para facilitar estes cálculos.
- ESP : ponteiro do topo da pilha (stack pointer)
- EBP : ponteiro da base da pilha (base pointer)
- ESI : índice de origem (source index) : mantém a localização dos dados de entrada
- EDI : índice de destino (destination index) : mantém a localização onde o dado do resultado da operação é armazenado
- EIP : ponto de instrução (instruction pointer) : mantém o ponto de memória do código da próxima instrução
Os registradores ESP, EBP e EIP são os mais interessantes e utilizados quando o assunto é Buffer Overflow. Conforme descrito acima e ilustrado na imagem abaixo, o registrador ESP aponta para o início do stack (menor endereço de memória) e o EBP para o final do stack (maior endereço de memória). E o EIP mantém o endereço da próxima instrução a ser executada, por isso, para que a aplicação execute o que desejamos nosso primeiro objetivo em um Buffer Overflow será controlar o EIP.
[caption id=”attachment_1831” align=”alignnone” width=”300”] Stack Frame[/caption]
Stack Frame[/caption]
Registradores
Em uma arquitetura 32 bits todos os registradores de uso geral possuem 32 bits (4 bytes) de tamanho e em um código assembly podem ser referenciados como 32 ou 16 bits. Por exemplo o EAX é a referencia para 32 bits inteiro e AX é a referencia para 16 bits menores do registrador EAX.
Quatro registradores (EAX, EBX, ECX e EDX) podem ser referenciado também com 8 bits, para 8 bits mais baixo ou o segundo 8 bits mais baixo, AL e AH respectivamente. A imagem abaixo visa demonstrar de forma gráfica essas diversas formas de utilização dos registradores.
[caption id=”attachment_1833” align=”alignnone” width=”300”] Registradores[/caption]
Registradores[/caption]
Pilha (stack)
Segundo Foster, A pilha “é uma área de memória usada para manter/armazenar dados temporários. A pilha cresce e reduz durante a execução da aplicação.” e após a definição incrementa a informação onde “Buffer Overflow comuns ocorrem na área de memória da pilha” conceito este que veremos logo a seguir como funciona o Stack Buffer Overflow.
A utilização primária da pilha é a troca de dados entre funções. A pilha tem uma arquitetura caracterizada por PUSHs e POPs em um modelo LIFO (last in, first out), ou seja, o ultimo dado a entrar na pilha será o primeiro a sair. Por exemplo, se você empilha (PUSH) os números 1, 2 e 3 nessa ordem, o primeiro número a ser desempilhado será o 3 pois ele foi o último a ser empilhado.
Para alguns ataques mais avançados de Buffer Overflow é extremamente importante entender esse funcionamento e como a manipulação do ESP + a arquitetura LIFO funciona. Se você deseja acessar a pilha diretamente, isso é possível usando o registrador ESP (Stack Pointer), que por sua vez aponta para o top da pilha (menor endereço de memória).
- Após um PUSH, o ESP irá apontar para um endereço menor (o endereço será decrementado com o tamanho do dado que foi inserido na pilha, em caso de endereço ou ponteiro será 4 bytes)
- Depois de um POP, o ESP irá apontar para um endereço maior (o endereço será incrementado com o tamanho do dado que foi retirado da pilha, em caso de endereço ou ponteiro será 4 bytes)
Stack Buffer Overflow
Usando o trecho de código C abaixo
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <string.h>
#include <stdio.h>
void function1(char *str){
char buffer[5];
strcpy(buffer, str);
}
void main(int argc, char *argv[])
{
function1(argv[1]);
printf("%s\n", "Executed normally");
}
Este código, bem simples por sinal, não faz muita coisa útil, mas é extremamente importante para entendermos os conceitos desejados.
Após compilado a execução dessa aplicação, via linha de comando será: overflowteste.exe AAAA
Note que a função main resgata o primeiro parâmetro passado pela linha de comando (AAAA) e preenche como parâmetro da função function1, que por sua vez irá copiar este valor dentro da variável local que detém o tamanho máximo de 5 caracteres (bytes).
Estes 5 bytes são teóricos, pois como essa variável é uma cadeia (array) de caracteres ela se utiliza de uma função de proteção que o C detém, essa função de proteção sempre adiciona ao final de uma string um caractere conhecido como nullbyte (0), que tem sua representação em hexa 0x00. O nullbyte tem a função de proteger a aplicação e é comumente utilizado nas operações com string para indicar para a aplicação que ali finalizou a string (cadeia de caracteres). Desta forma como a aplicação automaticamente adicionará o nullbyte ao final do nosso texto, teremos a quantidade de caracteres passadas por parâmetro mais o nullbyte, então se passarmos 5 As mais o nullbyte já teríamos uma condição de buffer overflow, pois a variável local só suporta 5 bytes e neste caso teríamos 6.
Na linha 11 do código temos a chamada da função function1, sendo assim uma nova pilha será criada para essa função e teremos algo parecido com a imagem abaixo
[caption id=”attachment_1837” align=”alignnone” width=”300”]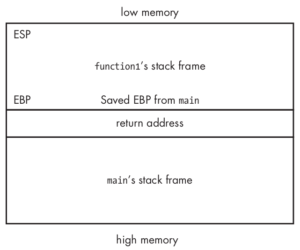 Pilha (stack) após a chamada da função function1[/caption]
Pilha (stack) após a chamada da função function1[/caption]
Note que temos o ESP no topo da pilha, a pilha (que neste caso terá o conteúdo que foi passado para a função) depois a base da pilha (EBP) e por fim o endereço de retorno (EIP), que neste ambiente será o endereço de memória da linha 12 da nossa aplicação, ou seja, o endereço que será utilizado pela nossa aplicação depois que a function1 fizer todo o seu trabalho e a aplicação precisa seguir o fluxo de execução.
Em uma execução da aplicação teremos o seguinte retorno:
1
2
overflowtest.exe AAAA
Executed normally
Agora se executarmos a aplicação com um texto maior que 4 caracteres (conforme a linha de comando abaixo), iremos causar a falha na aplicação e teríamos algo similar a imagem abaixo
1
overflowtest.exe AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
[caption id=”attachment_1840” align=”alignnone” width=”300”]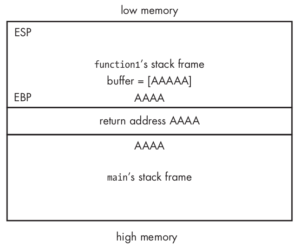 Memória depois do strcpy[/caption]
Memória depois do strcpy[/caption]
Conforme podemos ver na imagem acima, estouramos o espaço de memória inicialmente atribuído para a variável local (5 bytes), de forma que substituímos diversas informações inclusive (e o mais importante) o endereço de retorno. Neste caso hipotético a aplicação tentará executar o endereço de memória 41414141 (a representação em hexadecimal dos 4 As) o que vai causar uma falha na aplicação pois o endereço de memória 41414141 não faz parte dessa aplicação causando então uma falha de segmentação (segmentation fault).
Um alerta aos navegantes: Este é um exemplo básico de stack buffer overflow e sempre temos que tem em mente que até o momento não comentamos de algumas proteções de memória que o Windows em versões mais novas detém como: data execution prevention (DEP) e address space layout randomization (ASLR). Assuntos estes que serão abordados em posts futuros. Sendo assim quando forem brincar com isso use um Windows XP ou Windows Vista.
Considerações finais
Estes foram os conceitos básicos que quis trazer para vocês, espero que tenha sido claro e consistente nos assuntos, que de certa forma são novos e confusos para muitos.
Segue o link do próximo post (Parte 1 - Stack Buffer Overflow), onde veremos na prática como realizar um Buffer Overflow.
Fontes:
- https://www.corelan.be/index.php/2009/07/19/exploit-writing-tutorial-part-1-stack-based-overflows/
- Penetration Testing: A Hands-On Introduction to Hacking de Georgia Weidman
- Buffer Overflow Attacks: Detect, exploit, prevent de James C. Foster
De forma complementar a este post segue um vídeo com a explicação dos conceitos base do Buffer Overflow: